안녕하세요 pulluper 입니다!
이번 포스팅에서는 timm 모듈을 이용하여 평가한 vit(vision transformer) classification성능을 정리 해보겠습니다.
timm 모듈은 hugging face에서 만들어주신 다음 레포에서 확인 할수 있습니다. (너무 감사합니다!)
https://github.com/huggingface/pytorch-image-models
GitHub - huggingface/pytorch-image-models: PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, E
PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, EfficientNetV2, NFNet, Vision Transformer, MixNet, MobileNet-V3/V2, RegNet, DPN, CSPNet, and more - GitHub - hugg...
github.com
vision transformer, parameter 구하는 방법과 Imagenet에 대한 기본적인 이해는 다음 포스팅을 참고해주세요.
[DNN] VIT(vision transformer) 리뷰 및 코드구현(CIFAR10) (ICLR2021)
Introduction 안녕하세요 pulluper입니다. 👏 이번 포스팅에서는 NLP에서 강력한 성능으로 기준이 된 Transformer (Self-Attention)을 vision task에 적용하여 sota(state-of-the-art)의 성능을 달성한 ICLR2021에 발표된 vi
csm-kr.tistory.com
[pytorch] network parameter 갯수 확인
1. print(sum(p.numel() for p in model.parameters() if p.requires_grad)) 예를들어 다양한 모델에 대하여 from torchvision.models import * if __name__ == '__main__': model = vgg11() print("vgg11 : ", sum(p.numel() for p in model.parameters() if p.
csm-kr.tistory.com
ILSVRC(Imagenet classification)validation set torchvision 으로 성능평가하기
안녕하세요! "pulluper" 입니다. 이번 포스팅에서 다룰 주제는 ILSVRC(Imagenet) 에 대한 설명과 torchvision library 를 통한 Imagenet validation set 성능평가 입니다. Detection 혹은 Network 관련 논문을 4개정도 뽑아
csm-kr.tistory.com
이 포스팅에서는 timm을 이용한 vit 관련 imagenet classification 성능을 평가하는 방법을 알아볼 것입니다.
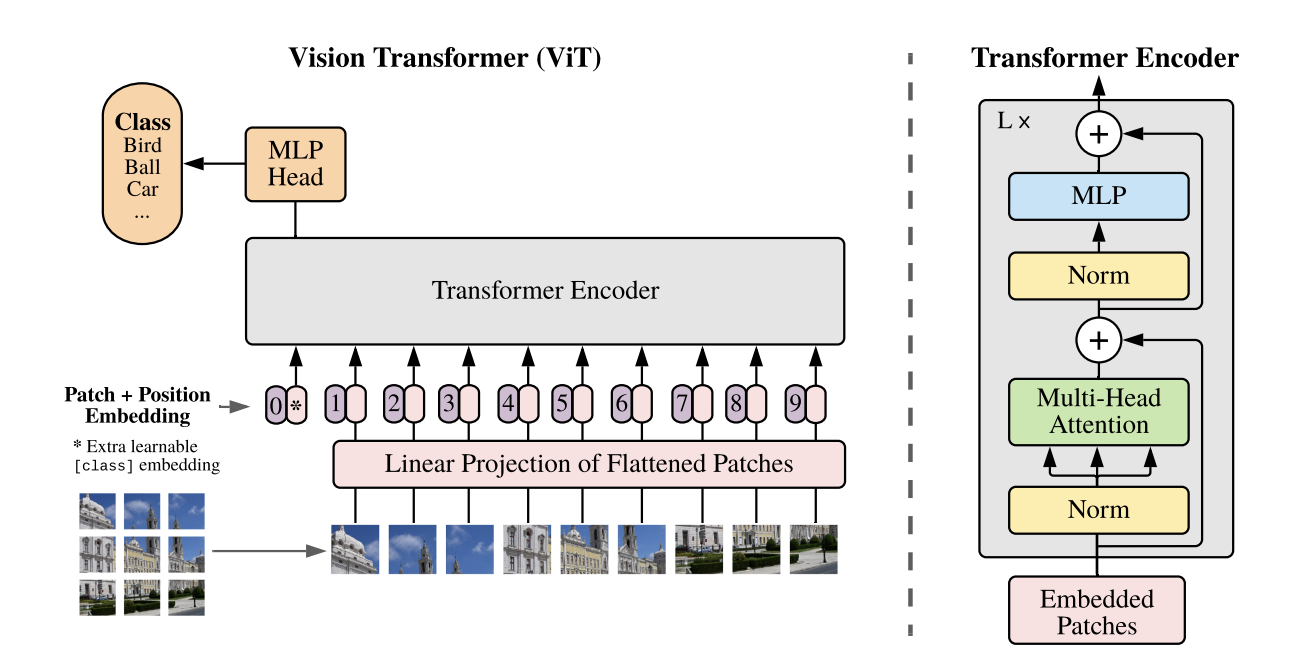
timm vit 모델의 특징은 다음과 같습니다.
- normalize 할 때, mean, std 가 [0.5, 0.5 0.5] 입니다.
- 학습 : ImageNet-21k 로 pretrained, ImageNet 으로 fine tuning
성능 평가 코드는 다음과 같습니다.
import timm
import torch
import torchvision
import torch.utils.data as data
import torchvision.transforms as transforms
if __name__ == "__main__":
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5])
transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
test_set = torchvision.datasets.ImageNet(root="D:\data\imagenet", transform=transform, split='val')
test_loader = data.DataLoader(test_set, batch_size=100, shuffle=True, num_workers=4)
model = timm.models.vit_base_patch16_224(pretrained=True).to(device)
# model = timm.models.vit_large_patch16_224(pretrained=True).to(device)
print(sum(p.numel() for p in model.parameters() if p.requires_grad))
model.eval()
correct_top1 = 0
correct_top5 = 0
total = 0
with torch.no_grad():
for idx, (images, labels) in enumerate(test_loader):
images = images.to(device) # [100, 3, 224, 224]
labels = labels.to(device) # [100]
outputs = model(images)
# ------------------------------------------------------------------------------
# rank 1
_, pred = torch.max(outputs, 1)
total += labels.size(0)
correct_top1 += (pred == labels).sum().item()
# ------------------------------------------------------------------------------
# rank 5
_, rank5 = outputs.topk(5, 1, True, True)
rank5 = rank5.t()
correct5 = rank5.eq(labels.view(1, -1).expand_as(rank5))
# ------------------------------------------------------------------------------
for k in range(6):
correct_k = correct5[:k].reshape(-1).float().sum(0, keepdim=True)
correct_top5 += correct_k.item()
print("step : {} / {}".format(idx + 1, len(test_set) / int(labels.size(0))))
print("top-1 percentage : {0:0.2f}%".format(correct_top1 / total * 100))
print("top-5 percentage : {0:0.2f}%".format(correct_top5 / total * 100))
print("top-1 percentage : {0:0.2f}%".format(correct_top1 / total * 100))
print("top-5 percentage : {0:0.2f}%".format(correct_top5 / total * 100))


vit 모델들의 구성은 다음과 같습니다.
여기서 timm에서 바로 사용가능한 모델은 Base, Large 입니다.

그리고 pre-trained 학습 방법을 보면,
ViT-B는 90epoch의 Imagenet21k pre-trained 을 하였고,
ViT-L 는 Imagenet21k에 대하여 30/90 epoch의 pre-trained 을 하였습니다.
ViT-* 는 Imagenet 으로 300 epoch의 학습을 진행했습니다.
Models | Dataset | Epochs | Base LR | LR decay | Weight decay | Dropout

다음표에서 Top-1 Acc (P) 는 논문에서 제안하는 성능이고, Top-1 Acc, Top-5 Acc 는 timm을 이용해 구한 성능입니다.
| Network | Training Data | Top-1 Acc (P) | Top-1 Acc | Top-5 Acc | Parameters |
| VIT-B | Imagenet 21K+1k | 83.97 | 84.44 | 97.25 | 86567656 |
| VIT-B | Imagenet 1K | 77.91 | - | - | - |
| VIT-L | Imagenet 21K+1k | 85.15 | 85.63 | 97.75 | 304326632 |
| VIT-L | Imagenet 1K | 76.53 | - | - | - |
'Network' 카테고리의 다른 글
| [DNN] Swin Transformer 리뷰 및 구현 (ICCV 2021) (5) | 2023.04.12 |
|---|---|
| [DNN] torchvision module 이용해서 resnet-dc5 구현하기 (2) | 2023.03.21 |
| [DNN] multi-head cross attention vs multi-head self attention 비교 (0) | 2023.02.02 |
| performer 구현 (0) | 2022.12.12 |
| [DNN] VIT(vision transformer) 리뷰 및 코드구현(CIFAR10) (ICLR2021) (3) | 2022.09.11 |



댓글