
안녕하세요 pulluper 입니다. 😀
이번 포스팅은 CVPR2016에 발표된 많은 network의 backbone이 되는 resnet 에 대한 리뷰와 구조에 대한 이해를 해보겠습니다. 저자는 Kaming He 님께서 1저자로 있으시네요. 자그럼 시작해보겠습니다.
Intro
그냥 생각하기에 깊은 neural network는 더 많은 parameter를 가지고 있고 더 좋은 representation power를 이용할 수 있어서 성능이 좋을것 같지 않나요? 당시의 네트워크의 발전양상도 더 깊은 네트워크를 쌓는 방향으로 (VGG) 발전이 되었습니다. 그러나 깊은 네트워크는 다음과 같은 문제가 있습니다. "Gradient vanishing/Gradient exploding"
다음 블로그에서 문제에 대한 좋은 비유를 얻을 수 있었습니다.
https://ratsgo.github.io/deep%20learning/2017/09/25/gradient/
그래디언트 디센트 · ratsgo's blog
이번 글에서는 그래디언트 디센트(Gradient Descent)에 대해 살펴보도록 하겠습니다. 이 글은 고려대 강필성 교수님 강의와 하용호 님의 자료를 정리했음을 먼저 밝힙니다. 그럼 시작하겠습니다. 산
ratsgo.github.io
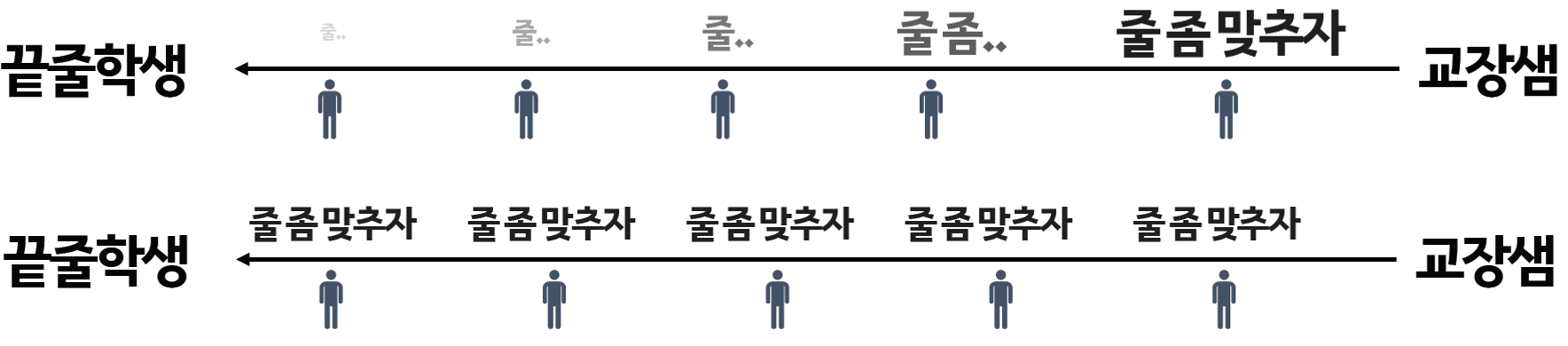
위의 그림에서 첫번째 전달은 교장선생님의 말이 점점 옅어지는 것 입니다. 이 문제는 깊어질수록 gradient 전파가 어려워지는 gradient vanishing 문제로 볼 수 있습니다. 이는 activation 함수와 normalization 방법을 사용하여 해결하려 했습니다.
이번에는 gradient exploding 입니다. https://github.com/NVIDIA/waveglow/issues/122
Loss explodes after 740 epochs · Issue #122 · NVIDIA/waveglow
Hi, I'm training on a custom dataset. My loss is exploding after 740 epochs. Any ideas on how to fix this? I've tried changing the the learning rate to 1e-5 from the best, most-recent check...
github.com
다음은 너무 가슴아픈 그림입니다. loss의 SGD등으로 gradient를 update 를 할 때, data의 문제 혹은 연산(log 0, 0으로 나누기) 등의 문제로 gradient 가 크게 뛰거나 nan, inf 등으로 가서 수렴이 어려워지는 현상입니다. 이는 각 연산이나 data의 문제를 해결 하거나 learning rate 등을 를 더 작게 조절, gradient clipping 등으로 해결하려 합니다.
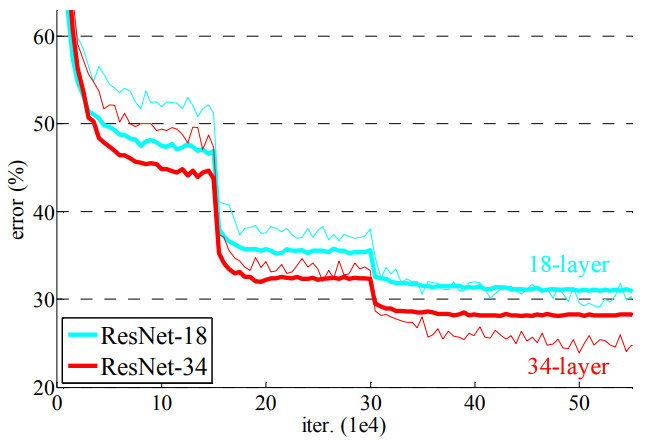
이러한 문제들이 있는데 여러 연구들로 network 를 converging 시키기 시작하였습니다. 그러나 깊은 네트워크는 성능이 떨어지는 degradation 문제가 있다고 합니다. 그림을 보시면 오히려 더 깊은 56-layer의 네트워크가 얕은 20-layer 의 네트워크보다 training, test 성능이 낮습니다. 이것이 degradation 문제입니다.

이 논문에서는 다음과 같이 더 깊은 친구가 더 좋은 성능을 내기위한 deep residual learning 을 제안합니다.
Method
이 논문에서 제안하는 방식은 deep residual learning 입니다. 다음의 예를 통해서 한번 알아보겠습니다. 만약 사과를 분류하는 네트워크를 만든다고 하고, H(.) : 목표로 하는 mapping, f(.) 는 VGG 등의 deep neraul network 입니다.
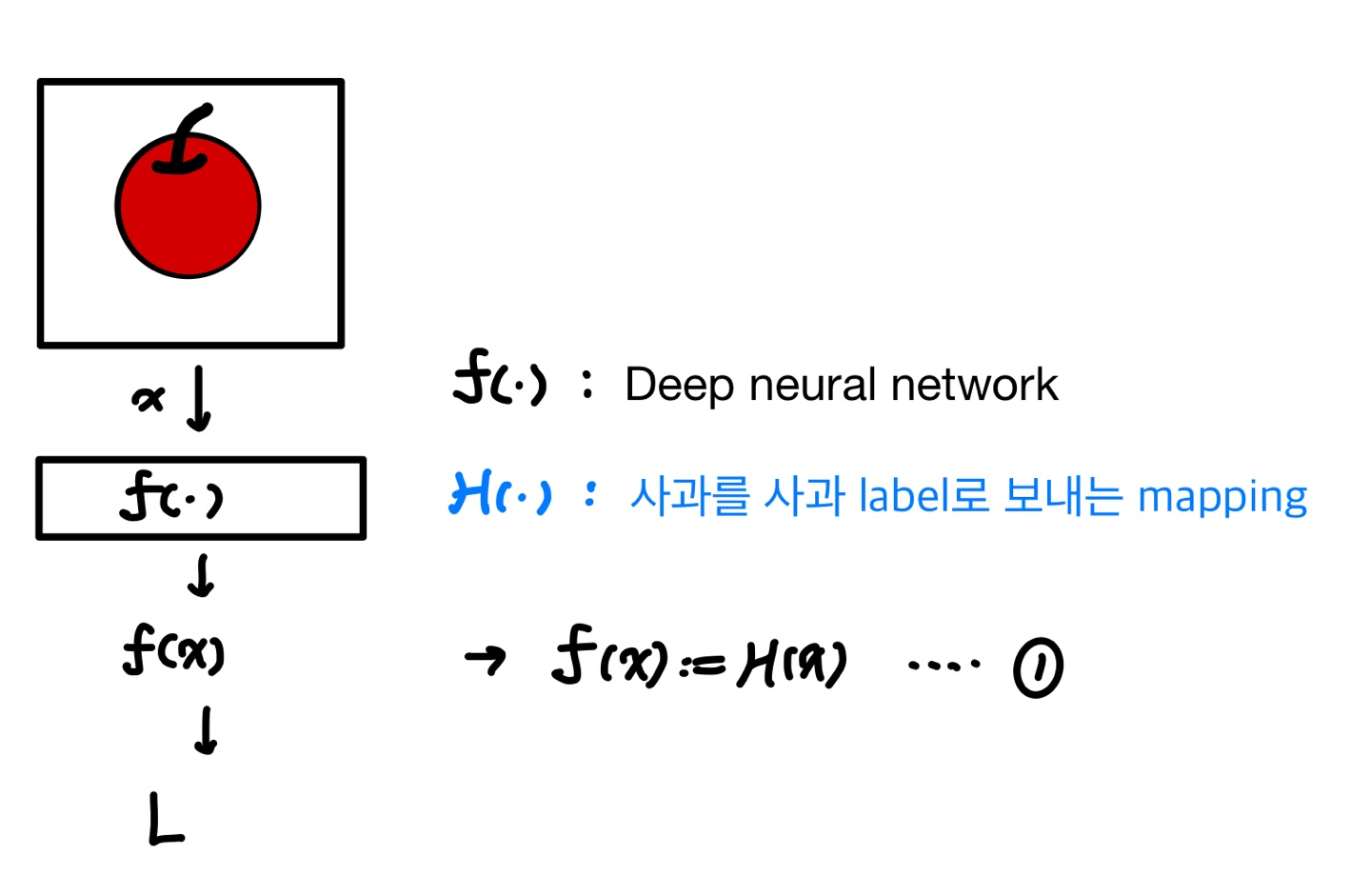
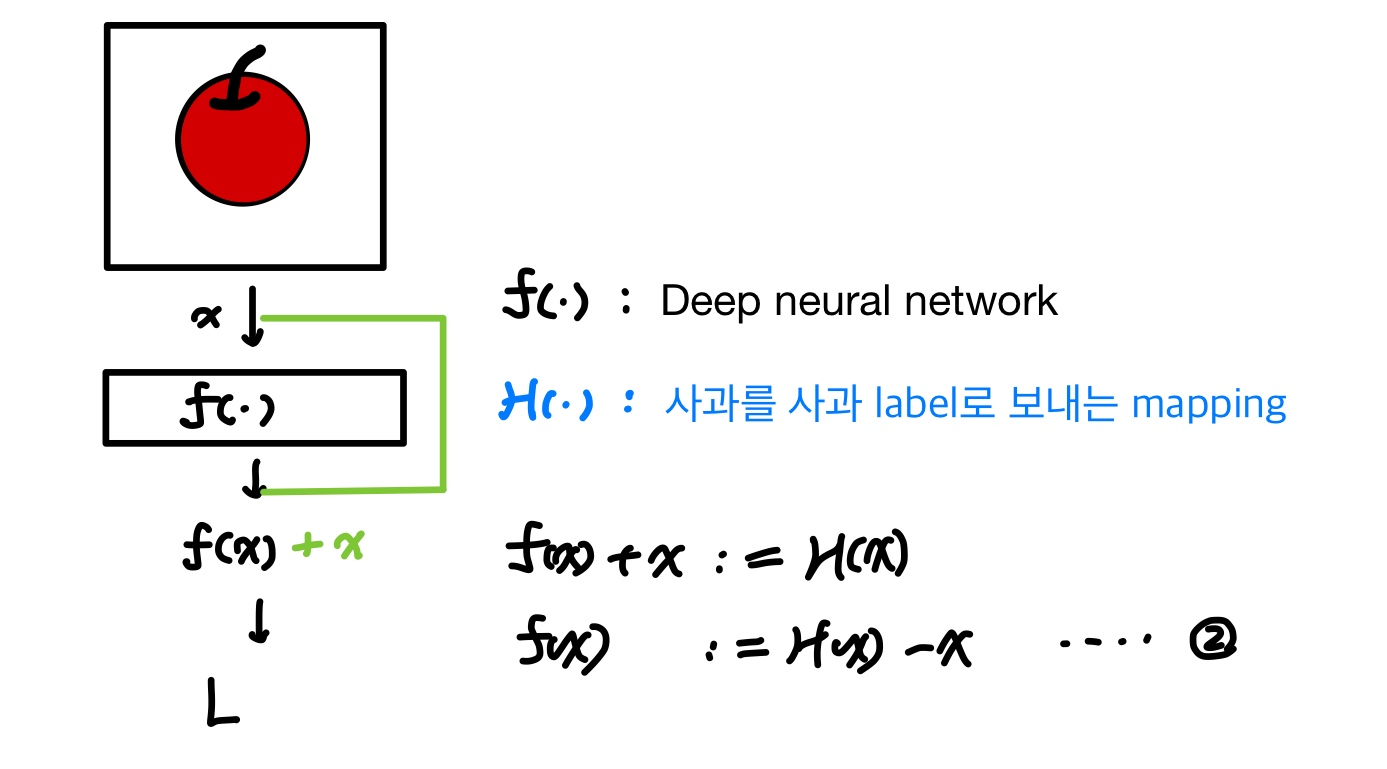
왼쪽 그림인 기존 방법에서 우리는 만들어진 deep neural netwrok f(x) 가 사과분류 mapping 인 h(x) 처럼 되는것을 원합니다. 즉 네트워크는 f(x) := H(x) 이 되도록 f를 학습합니다.
오른쪽 그림인 residual leraning 은 deep neural netwrok f(x)에 자기자신(x) 를 추가로 더한 f(x) + x가 h(x) 가 되게 하는 방식입니다. 실제 학습되는 f가 그냥 H가 아닌 f(x) := H(x) - x 의 residual을 학습하게 하고 논문에서는 (1) 수식보다 (2) 수식을 optimize 하는게 더 쉽다고 가정하고 있습니다.

여기까지는 논문의 내용이고, 감사하게도 다음 블로그에서 resnet 이 잘 되는 이유에 대한 논문을 엿볼 수 있었습니다.
8. CNN 구조 3 - VGGNet, ResNet
안녕하세요, 라온피플(주)입니다. 아래와 같이 총 19회의 포스팅을 통해 Deep Learning 알고리즘에 대해 ...
blog.naver.com
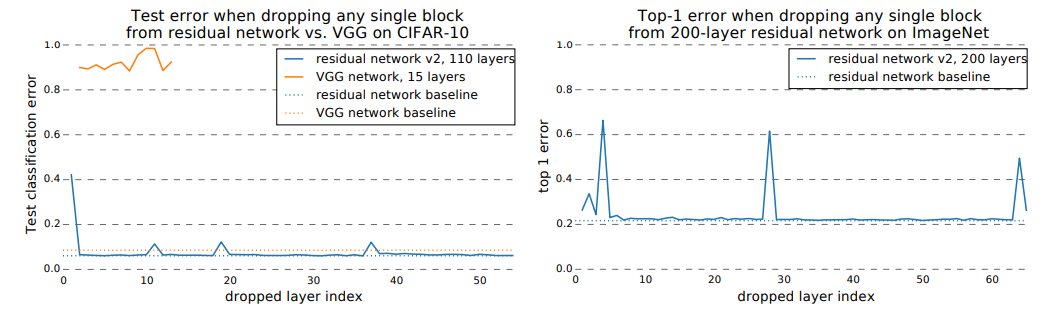
다음 그림은 위 블로그에서 소개하는 "Residual Networks Behave Like Ensembles of Relatively Shallow Networks"(NIPS2016) 라는 논문에서 VGG와 Resnet에 대하여 각각 layer 를 삭제하면서 성능을 비교한 것입니다. VGG는 성능이 매우낮고, 학습이 안되는것 같지만 resnet 은 특정 layer가 없더라도 학습이 가능합니다.
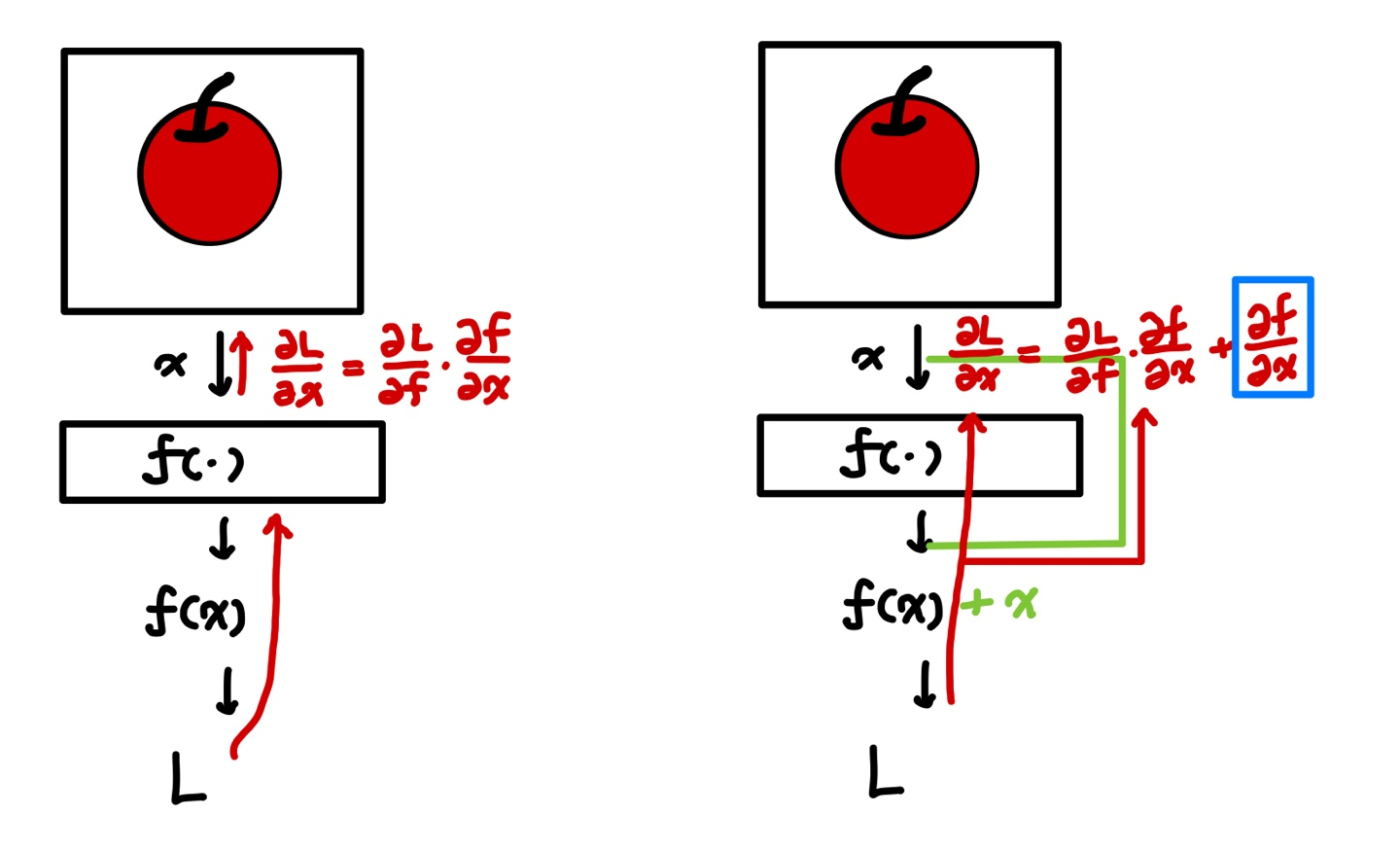
이것을 다음과 같이 해석 할 수 있습니다. 아래 그림에서 두 case 에 대하여 update 하는 부분을 보겠습니다. L에 대한 x의 gradient 는 왼쪽에서는 모두 곱으로 이루어졌지만, residual leanring 에서는 파란색 박스인 더해지는 값이 있습니다. 이를 통해 왼쪽과 같이 모두 이어진 VGG layer에 비해 Resnet 의 layer는 gradient가 독립적으로 유지될 가능성이 높고 이런이유로 emsemble처럼 resnet이 작동하며, degradation의 문제를 해결한것 같습니다.
더 자세한 내용은 다음 논문을 읽어보시는 것을 추천합니다.
Structure
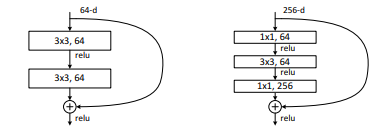
Resnet 다음과 같은 Block 구조들을 통해서 단순한 deep nueral 네트워크를 변경합니다. 왼쪽은 basic block 오른쪽은 bottleneck block 입니다.
전체 구조는 다음과 같은데 18, 34l ayer 는 Basic block 을 사용하고, 나머지는 Bottleneck block 을 사용합니다.
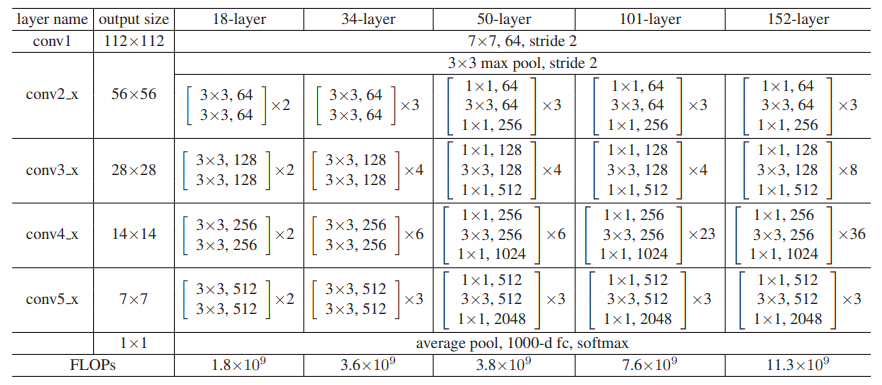
Resnet 50 에 대한 구조의 detail을 잠깐 보면, 다음과 같습니다.

그리고 몇가지 특성이 있습니다. (pytorch torchvision.model.resnet50 참조)
1. 처음에 7x7 convolution 연산을 한다.
2. 모든 convolution은 bias가 없고 same padding 을 한다.
3. Layer 의 첫번째 Bottleneck에서만 downsample 을 하고 추가적인 convolution 연산이 있다. (type1)
4. downsample 시 (maxpool, conv 모두) ceil = True 연산을 한다. e.g.) [2 x 128x 75 x 75] -> [2 x 128x 38 x 38]
Experiments
네 마지막으로 성능과 실험을 알아보겠습니다.
먼저 이미지넷의 실험 환경은 다음과 같습니다.
- batch size :256
- iterations : 60000 iters
- epoch : 234 epoch
- init lr : 1e-1
- optimizer : SGD
- weight decay : 0.0001
- momuntum : 0.9
- lr scheduler : div 10 when the error plateaus
다음은 실험에 대한 결과입니다.

imagenet 에서 VGG, GoogLeNet 보다 좋은 성능을 보이며 많이 쌓아도 성능이 증가하는 모습을 보였습니다.

그리고 위의 그림을 통해서 plain 과 resnet 에서의 깊이 쌓았을때의 degradation 문제를 어느정도 해결한것으로 보였지만 마지막 resnet110 과 resnet1202 에서는 여전히 너무 깊은 layer에서는 degradation 문제가 있는것으로 보였습니다. degradation 문제를 완전히 해결한것이 아닌 약간 뒤로 미루게 한 느낌입니다.
이후에 이러한 residual learning의 개념과 resnet 은 다양한 task 에서 backbone 으로 많이 사용되었고 우리는 많은 library 를 통해서 (e.g. pytorch, tensorlow 등..) 다음과 같이 몇줄로 사용할 수 있습니다. 👍👍👍👍👍
from torchvision.models import resnet50
model = resnet50()이번에는 Resnet 에 대하여 알아보았는데요. 😎😎😎
질문과 토론은 언제든지 환영합니다. 감사합니다.
'Network' 카테고리의 다른 글
| performer 구현 (0) | 2022.12.12 |
|---|---|
| [DNN] VIT(vision transformer) 리뷰 및 코드구현(CIFAR10) (ICLR2021) (3) | 2022.09.11 |
| [DNN] VGG구현을 위한 리뷰(ICLR 2015) (0) | 2022.07.27 |
| [DNN] ViT 구조 (1) | 2022.06.08 |
| [DNN] Alexnet 리뷰 및 구현 (NIPS 2012) (0) | 2021.09.24 |



댓글