
안녕하세요 pulluper :) 입니다!
오늘은 deep learning 의 시대로 이끌었다고 해도 과언이 아닌 그 논문!
Alexnet 에 대하여 알아보겠습니다.
저자분들은 다음과 같은데 딥 러닝 분야에서 가장 유명하신분들 입니다.

논문은 다음 링크 [here] 에서 보실 수 있고 저는 실제 구현에 필요한 부분에 집중하여 리뷰를 해 보겠습니다.
이 논문이 주목받았던 이유중 하나는 ILSVRC 라는 이미지 인식 대회에서 이전, 그리고 동년도의 알고리즘들에 비해
월등한 성능을 가진 인식 알고리즘을 개발했기 때문이기도 한데요,
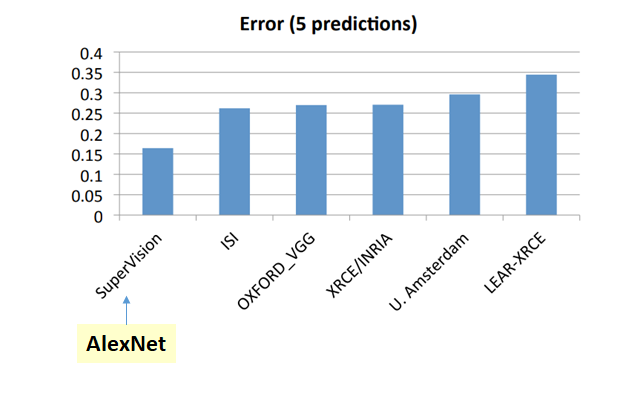
다음 그림의 왼쪽은 연도별 ILSVRC의 성능이고, 오른쪽은 alexnet 이전에 알고리즘들과의 비교를 나타냅니다.
2012년에 그전에 0.26 인 error rate 가 0.16 으로 확 떨어진 것을 볼 수 있습니다.
현재는(2021년 9월 기준) 거의 더 발전된 기술로 top-1 error 조차도 90% 를 넘는 알고리즘들이 등장 하고 있습니다.

이 논문은 엄청 유명한 논문이니만큼 딥 러닝 공부의 기본이라고 생각 할 수 있습니다.
이러한 DNN 논문들은 보통 pytorch 등의 library 등에서 잘 학습된 parameter 들을 제공해 주기에,
저도 논문을 읽고 구현을 하기보다는 필요에 의해 사용을 했습니다.
그런데 실제로 실험을 해 보았을 때 성능이 논문처럼 나오지 않았기에 어느 부분에서
Accuracy drop 이 나오는지 분석을 해 보았습니다. 🤣
구현에 필요한 부분들을 다음과 같이 나누었습니다.
1. Dataset
2. Model
3. Loss
4. Training
5. Test(Evaluation)
1. Dataset
자 먼저 dataset 부분입니다. 저는 Large Scale 의 dataset 인 Imagenet 을 기준으로 한 실험을 해 보고 싶었기에
이미지넷을 사용하였습니다. 이미지넷 데이터에 대한 정보와 성능평가를 쉽게 하는 방법은 다음을 참고하시길 바랍니다.
ILSVRC(Imagenet classification)validation set torchvision 으로 성능평가하기
안녕하세요! "pulluper" 입니다. 이번 포스팅에서 다룰 주제는 ILSVRC(Imagenet) 에 대한 설명과 torchvision library 를 통한 Imagenet validation set 성능평가 입니다. Detection 혹은 Network 관련 논문을 4개..
csm-kr.tistory.com
이미지넷 dataset은 1000개의 class를 분류하는 문제입니다.
training dataset : 1281167 개, test datsaet : 100000개, validation dataset : 50000개로 구성되어 있습니다.
test dataset은 공식 홈페이지 Evaluation Server통해서 실험 해 볼수 있기 때문에
편의를 위해 validation dataset 을 성능의 지표로 이용하곤 합니다.
이 데이터셋을 다운받는 방법은 공식 사이트에서 로그인을 한 후 비상업적 연구/교육적 목적을 동의하고 다운을 받을 수 있게 합니다. 혹은 연구 토렌트를 이용한 방법등이 있습니다.
1-1. Data augmentation
dataset 에서 중요한 부분은 data augmentation입니다.
논문에서는 scale을 위한 augmentation 과 RGB intensity를 변경하는 augmentation을 사용합니다.

위 글에서 보면 먼저 imagenet 을 256 x 256 으로 resize 를 합니다.
이후 224 x 224 의 random patch 로 자릅니다. 이후 (random) horizontal reflection 을 사용합니다.
이부분을 pytorch torchvision.transforms의 다음 함수들로 나타낼 수 있습니다.
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
두번째 augmentation 은 RGB channels를 변경하는 방식인데, 찾아봤을 때는 pytorch에서는 찾을 수 없었습니다. 그 내용은 다음과 같습니다.

imagenet dataset 의 모든 이미지의 rgb pixel 에 대한 covariance matrix 를 만듭니다.
여기서 cov matrix 에 대한 고윳값 분해를 통해서 이 matrix 의 eigenvector, eigenvalue를 찾아냅니다. 그것이 각각
p, $\lambda$ 입니다. 자 그리고 $\alpha$ 는 Normal distribution (0, 0.1) 의 3차원 값입니다.
그리고 위 문단에서 alpha 를 전체 이미지가 한번 훈련하고 다시 사용될까지 사용하고 바꾼다고 하여서, epoch 별로 alpha 를 다시 sampling 하면서 학습하게 하였습니다. 이렇게 바꾸게 되면 얻는 효과는 RGB의 intensity 가 바뀌어서 색이 바뀌게 됩니다. (아래 사진은 alpha =0.5 일때) 이러한 augmentation가 top-1 error 를 1 % 올린다 하였습니다.


이를 위해서 PCANoisePIL이라는 클래스를 만들어서 다음과 같이 사용했습니다.
import numpy as np
from PIL import Image
class PCANoisePIL(object):
def __init__(self,
alphastd=0.1,
eigval=np.array([55.46, 4.794, 1.148]),
eigvec=np.array([[-0.5675, 0.7192, 0.4009],
[-0.5808, -0.0045, -0.8140],
[-0.5836, -0.6948, 0.4203],])
):
self.alphastd = alphastd
self.eigval = eigval
self.eigvec = eigvec
self.set_alpha()
def __call__(self, img):
# 1. pil to numpy
img_np = np.array(img) # [H, W, C]
offset = np.dot(self.eigvec * self.alpha, self.eigval)
img_np = img_np + offset
img_np = np.maximum(np.minimum(img_np, 255.0), 0.0)
ret = Image.fromarray(np.uint8(img_np))
return ret
def set_alpha(self, ):
# change per each epoch
self.alpha = np.random.normal(0, self.alphastd, size=(3,))
각 eigenvalue, eigen vector는 다음에서 얻었습니다.
Does anyone have the eigenvalue and eigenvectors for Alexnet's PCA noise from the imagenet dataset?
Does anyone have the eigenvalue and eigenvectors for Alexnet's PCA noise from the imagenet dataset? The imagenet dataset has 12million images and my computer is unable to calculate PCA for such a ...
stackoverflow.com
실제 사용은 다음과 같이 transforms 사이에 넣으면 됩니다!
# 4. data
transform_train = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
PCANoisePIL(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])2. Model
알렉스넷은 5개의 convolution network 와 activation function들, maxpooling 으로 이루어졌습니다.

코드는 다음과 같습니다. (torchvision)
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x3. Loss
Task 가 (single label) classification 이기 때문에 기본적인 Cross Entropy Loss 를 사용합니다. 코드는 다음과 같습니다.
import torch.nn as nn
loss = nn.CrossEntropyLoss()4. Traning
training 과 관련된 부분은 다음과 같습니다.

- init learning rate: 0.01
- batch size: 128
- momentum: 0.9
- weight decay: 0.0005
- epoch: 90
- learning rate decay: validation error 가 개선되지 않을 때, 10 으로 나눠준다. (3번 - plateau)
- conv init: gaussian (0, 0.01)
5. Test (Evaluation)
하나의 이미지의 Center Crop을 한 후 top5, top1의 성능평가를 합니다. 이 deep neural network 를 이용한 성능은 그때 당시 매우 좋은 성능이였습니다. evaluation 코드는 다음과 같습니다.
import torch
import torchvision
import torch.utils.data as data
import torchvision.transforms as transforms
if __name__ == "__main__":
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
test_set = torchvision.datasets.ImageNet(root="D:\Data\example", transform=transform, split='val')
test_loader = data.DataLoader(test_set, batch_size=100, shuffle=True, num_workers=4)
model = torchvision.models.alexnet(pretrained=True).to(device)
model.eval()
correct_top1 = 0
correct_top5 = 0
total = 0
with torch.no_grad():
for idx, (images, labels) in enumerate(test_loader):
images = images.to(device) # [100, 3, 224, 224]
labels = labels.to(device) # [100]
outputs = model(images)
# ------------------------------------------------------------------------------
# rank 1
_, pred = torch.max(outputs, 1)
total += labels.size(0)
correct_top1 += (pred == labels).sum().item()
# ------------------------------------------------------------------------------
# rank 5
_, rank5 = outputs.topk(5, 1, True, True)
rank5 = rank5.t()
correct5 = rank5.eq(labels.view(1, -1).expand_as(rank5))
# ------------------------------------------------------------------------------
for k in range(6):
correct_k = correct5[:k].view(-1).float().sum(0, keepdim=True)
correct_top5 += correct_k.item()
print("step : {} / {}".format(idx + 1, len(test_set)/int(labels.size(0))))
print("top-1 percentage : {0:0.2f}%".format(correct_top1 / total * 100))
print("top-5 percentage : {0:0.2f}%".format(correct_top5 / total * 100))
print("top-1 percentage : {0:0.2f}%".format(correct_top1 / total * 100))
print("top-5 percentage : {0:0.2f}%".format(correct_top5 / total * 100))이번 포스팅에서는 DNN의 시대를 끌어내준. Alexnet 에 대하여 보았습니다. 다음 DNN포스팅은 VGG 를 보겠습니다.
토론과 댓글을 항상 환영합니다. 감사합니다. 😎😎😎
전체 구현은 다음에서 확인할 수 있습니다.
https://github.com/csm-kr/alexnet_pytorch
GitHub - csm-kr/alexnet_pytorch: re-implementation of alexnet
:octocat: re-implementation of alexnet . Contribute to csm-kr/alexnet_pytorch development by creating an account on GitHub.
github.com
Reference
https://www.bulentsiyah.com/imagenet-winning-cnn-architectures-ilsvrc
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
'Network' 카테고리의 다른 글
| [DNN] VGG구현을 위한 리뷰(ICLR 2015) (0) | 2022.07.27 |
|---|---|
| [DNN] ViT 구조 (1) | 2022.06.08 |
| [DNN] U-net 구조와 code 구현 (MICCAI2015) (4) | 2021.05.02 |
| [DNN] Densenet 논문리뷰 및 구현 (CVPR2017) (0) | 2021.04.13 |
| ILSVRC(Imagenet classification)validation set torchvision 으로 성능평가하기 (12) | 2021.03.01 |




댓글