
안녕하세요 PULLUPER 입니다.
최근에 Faster RCNN 정리와 구현을 해보았는데요.
DETR논문을 읽는중 Faster RCNN과의 비교를 해 놓은 부분을 보았습니다.
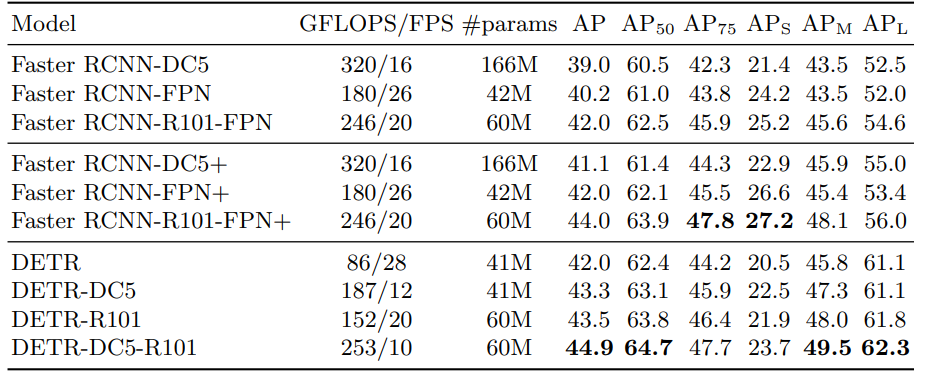
보시다시피, AP 가 COCO VAL set 에 대하여 39.0이 넘는 성능을 보였습니다. 이때 구현한 faster rcnn에 대하여 위 표와같이 성능이 올라가지는 실험을 통해서 알아보고 싶었습니다.
먼저 faster rcnn 구현과 설명은 다음 포스팅에 나와있습니다.
[Object Detection] Faster R-CNN (NIPS2016) 엄밀한 리뷰
안녕하세요! pulluper입니다 😀😀😀 이번 포스팅은 드디어 Faster RCNN을 분석을 해 보려 합니다. Faster RCNN은 2016년 NIPS 에 발표되었으며, 그 이후로도 2-stage object detection의 대표로 계속해서 사용되..
csm-kr.tistory.com
[Object Detection] Faster R-CNN (NIPS2016) 진행과정 및 코드구현
안녕하세요 Pulluper 입니다 😎 지난 포스팅에서 Faster RCNN 리뷰를 했는데 이번에는 구현의 큰 그림과, 코드를 보겠습니다. 리뷰는 다음 블로그를 참조하세요 :) https://csm-kr.tistory.com/30 [Object Detect..
csm-kr.tistory.com
이번포스팅은 어떻게 DETR 논문에서 Faster RCNN에 대한 성능을 높였는지 알아보는 부분을 집중적으로 보겠습니다.
DETR paper 에서 설명한 부분은 다음과 같습니다.

크게 4가지 부분을 개선시켰습니다.
1. RESNET 50/101 (MODEL)
2. GIOU LOSS (LOSS)
3. RANDOM CROPS (DATASET)
4. X9 TRAINING SCHEDULE (TRAIN)
MODEL, LOSS, DATASET, TRAIN 방식을 변화하면서 성능을 높인 것으로 보입니다. 포스팅은 다음 부분들을 하나씩 분석해 가면서 실제 실험과 함께 성능이 얼마나 오르는지 확인할 예정입니다.
1. Change Backbone: ResNet-50 and DC5 or FPN
원래 Faster RCNN 은 Backbone 으로 VGG16 을 사용했습니다.
그러나 이 실험에서는 ResNet 50/100을 사용하였습니다.
따라서 FasterRCNN-DC5/FPN에 대한 정보를 찾아보았는데, detectron2 홈페이지에서 구할 수 있었습니다.
https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md
GitHub - facebookresearch/detectron2: Detectron2 is a platform for object detection, segmentation and other visual recognition t
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks. - GitHub - facebookresearch/detectron2: Detectron2 is a platform for object detection, segmentation a...
github.com

DC5 는 ResNet conv5 백본에서 dilation conv를 사용한 것으로 추정됩니다.
facebook reasearch detectron2 자료에서 모델의 변경점을 볼 수 있습니다.
Detectron2 Tutorial.ipynb
Colaboratory notebook
colab.research.google.com
모델의 디테일을 보면 다음과 같습니다.

Resnet-DC5
모델은 다음과 같습니다.
여기서 기존의 resnet 과 달라진 부분이 몇개 있습니다.
1. bottleneck type1의 stride가 2일때 3x3 conv 의 stride가 변하는것에서 에서 맨앞의 1x1 conv stride 가 변한다.
2. resnet50 의 layer 4의 첫부분 bottleneck 이 stride 가 1이다.
3. layer 4의 bottleneck DC2는 그 BLOCK의 3x3 convolution 의 dilation 2이다. (padding : 2, stride : 1)
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)이 네트워크를 통과하면 [B, 3, 600, 600] 이미지는 [3, 2048, 38, 38] 이 됩니다.
Resnet-FPN
이 모델은 Resnet50 + FPN (feature pyramid network) 로 구성이 됩니다.
그리고 torchvision 을 통해서 다음과 같이 구현가능합니다.
from torchvision.models.detection.backbone_utils import resnet_fpn_backbone
from torchvision.models import ResNet50_Weights
import torch
resnet_fpn_backbone('resnet50', weights=ResNet50_Weights.IMAGENET1K_V1, trainable_layers=3)
x = torch.randn([2, 3, 800, 1000])
model = resnet_fpn_backbone('resnet50', weights=ResNet50_Weights.IMAGENET1K_V1, trainable_layers=3)
output = model(x)
print(model(x))이 네트워크를 통과하면 [B, 3, 800, 1000] 이미지는 다음 과 같은 OrderedDict 의 type을 갖습니다.
{[B, 256, 200, 250], [B, 256, 100, 125], [B, 256, 50, 63], [B, 256, 25, 32], [B, 256, 13, 16]}

결과는 다음과 같습니다.
이 실험은 coco dataset에 대하여 backbone을 vgg16에서 resnet50 + fpn으로 변경한 결과입니다.
| model | add1 | add2 | add3 | add4 | mAP(coco) |
| FRCNN(original) | 20.7 | ||||
| FRCNN(exp1) | model | 28.1 (+7.4) |
2. Change Loss: Smooth L1 with GIOU Loss
먼저 FRCNN Loss에 대하여 알아보면,
(gt) box : b anchor box : a 의 관계로 만들어진 target : t 에 대하여 loss를 줄이도록 설계가 되었습니다.
정리하면 다음과 같습니다.

여기서 encoding 하는것은 cxcywh coordinate를 갖는것에 주의해야 합니다.
이렇게 만들어진 t 는 딥뉴럴 네트워크 아웃풋인 t* (t_x*, t_y*, t_w*, t_h*) 와의 smooth l1 norm 으로 학습이 되었습니다.
t* 를 a 와의 연산을 통해서 예측 박스 b*를 만드는 것을 decoding 이라 하고 이는 다음과 같습니다.

decoding 또한 cxcywh coordinate 을 가지며 이는 prediction box 를 만들거나 roi를 만들 때 사용되었습니다.
그러나 gIoU loss 를 위해서는 x1y1x2y2 의coordinate 를 가져야 하므로 연산을 하기 위해 target을 만들 때,
decoding 방식이 필요합니다.
RPN에서는 box 와 roi - decoding(t*, anchor) 에 대한 giou loss와
FRCNN에서는 box 와 pred box - decoding(t*, sampled_roi) 에 대한 giou loss를 계산합니다.
이 과정을 추가 하였을 때, 결과로는 FRCNN이 약 1.8 더 오른 29.9 mAP를 가집니다.
| model | add1 | add2 | add3 | add4 | mAP(coco) |
| FRCNN(original) | 20.7 | ||||
| FRCNN(exp1) | model | 28.1 (+7.4) | |||
| FRCNN(exp2) | model | loss | 29.9 (+9.2) |
3. Change Augmentation: Flip to Random Crop like DETR
보통의 FRCNN의 data augmentation에서 DETR과 같은 data augmentation 을 적용합니다.
https://github.com/facebookresearch/detr/blob/main/datasets/coco.py#L115
GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers. Contribute to facebookresearch/detr development by creating an account on GitHub.
github.com
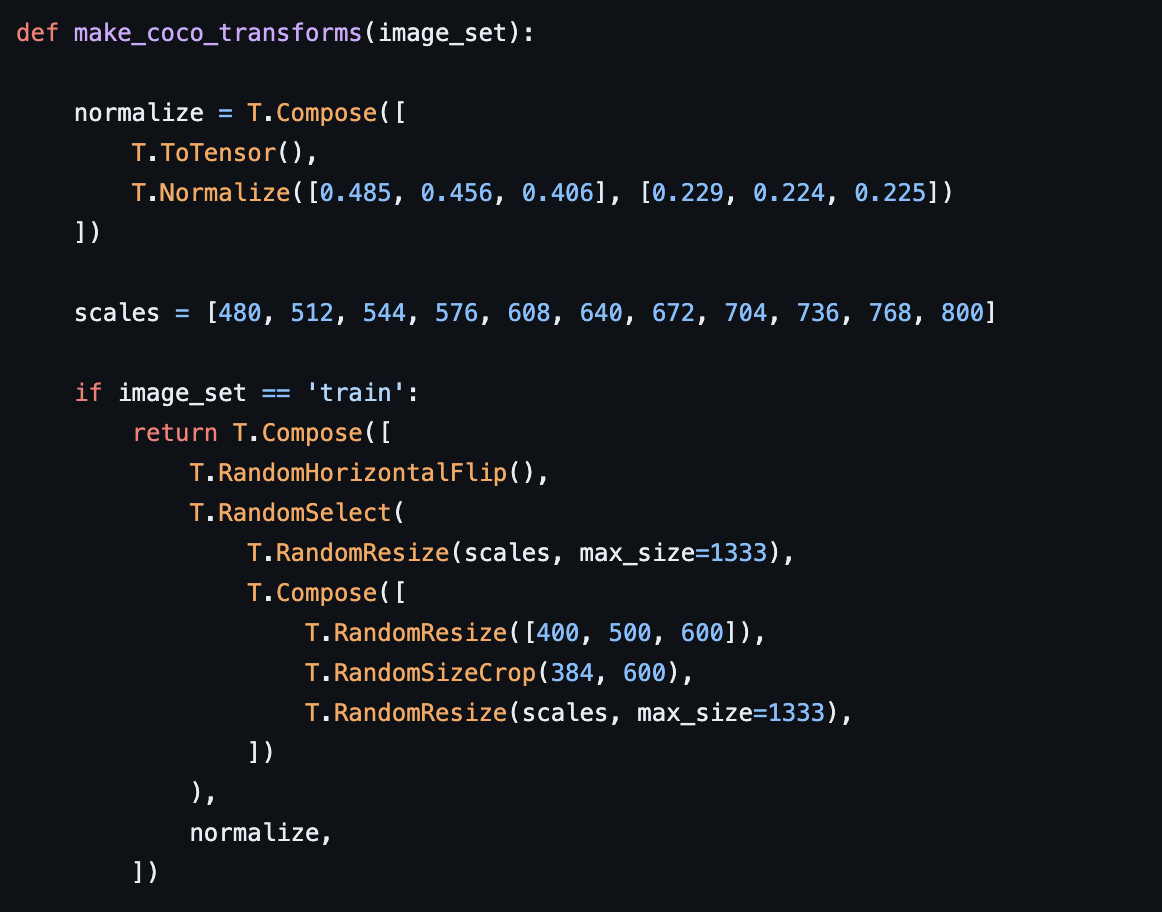
결과는 epoch이 기존 FRCNN 학습인 13(기본 학습 epoch)이기 때문에 오히려 낮아졌습니다.
이것이 도움이 되기 위해서는 충분히 큰 epoch 을 가져야 합니다.
이를 위해 마지막으로 LR 조절과 긴 epoch을 적용합니다.
| model | add1 | add2 | add3 | add4 | mAP(coco) |
| FRCNN(original) | 20.7 | ||||
| FRCNN(exp1) | model | 28.1 (+7.4) | |||
| FRCNN(exp2) | model | loss | 29.9 (+9.2) | ||
| FRCNN(exp3) | model | loss | data | 29.3 (-0.6) |
issue : 학습 할 때 max(0) 이 없는 경우 발생 - target에 아무것도 안들어 있다는 것! - 해결 (boxes가 0이 된다는 뜻)
4. Change Training Schedule: 13 epoch to 108 epoch
여태까지의 학습 환경은 다음과 같습니다.
Epoch : 13
Initial LR : 1e-3
Optimizer : SGD
Learning rate deacy : * 0.1 [At 8, 11 epoch]
이를 detectron2 에서의 학습과 같이 다음처럼 적용합니다.
Epoch : 109
Initial LR : 2e-2
Optimizer : SGD
Learning rate deacy : * 0.1 [At 64, 88 epoch]
| model | add1 | add2 | add3 | add4 | mAP(coco) |
| FRCNN(original) | 20.7 | ||||
| FRCNN(exp1) | model | 28.1 (+7.4) | |||
| FRCNN(exp2) | model | loss | 29.9 (+9.2) | ||
| FRCNN(exp3) | model | loss | data | 29.3 (-0.6) | |
| FRCNN(exp4) | model | loss | data | schedule + LR | 40.9 (+20.2) |
성능이 가장 크게 오른 부분입니다.
학습 코드는 다음 레포에서 볼 수 있습니다.
도움이 되셨다면 댓글 부탁드릴께요
감사합니다.
'Object Detection > RCNN Detection' 카테고리의 다른 글
| [Object Detection] Faster R-CNN (NIPS2016) 진행과정 및 코드구현 (0) | 2022.06.01 |
|---|---|
| [Object Detection] Faster R-CNN (NIPS2016) 엄밀한 리뷰 (1) | 2022.04.25 |
| [pytorch-torchvision] RoI Pooling 이해하기 및 예제 구현 (0) | 2022.04.22 |
| [Object Detection] Fast R-CNN(ICCV2015) 논문리뷰 (5) | 2022.01.05 |
| [Object Detection] R-CNN Follow-Up (0) | 2022.01.04 |




댓글