
안녕하세요 pulluper입니다. 😁
이번 포스팅에서는 torchvision을 이용한 RoI Pooling 를 알아보고 예제를 통해서 이해를 해 보도록 하겠습니다. RoI Pooling 이란 Fast RCNN에서 원하는 위치(regions)의 feature를 max pooling 하기 위한 layer 입니다. SPPnet의 하나의 피라미드 level에 대한 spatial pyramid pooling 과 동일합니다. 아래 사진을 보면 Regions 의 위치에 해당하는 feature를 동을한 크기의 feature로 만들기 위해 maxpooling 을 하는 것 입니다.
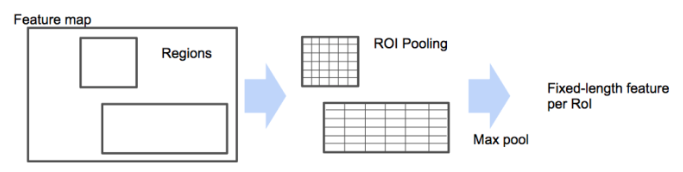
사진 출처 : https://github.com/hwkim94/hwkim94.github.io/wiki/Fast-R-CNN(2015)
GitHub - hwkim94/hwkim94.github.io: Data
Data. Contribute to hwkim94/hwkim94.github.io development by creating an account on GitHub.
github.com
만약 여러분들이 pytorch를 사용하신다면 torchvision 을 이용해서 RoIPool 을 적용 할 수 있습니다. 다음과 같이 import 가능합니다.
from torchvision.opts import RoIPool
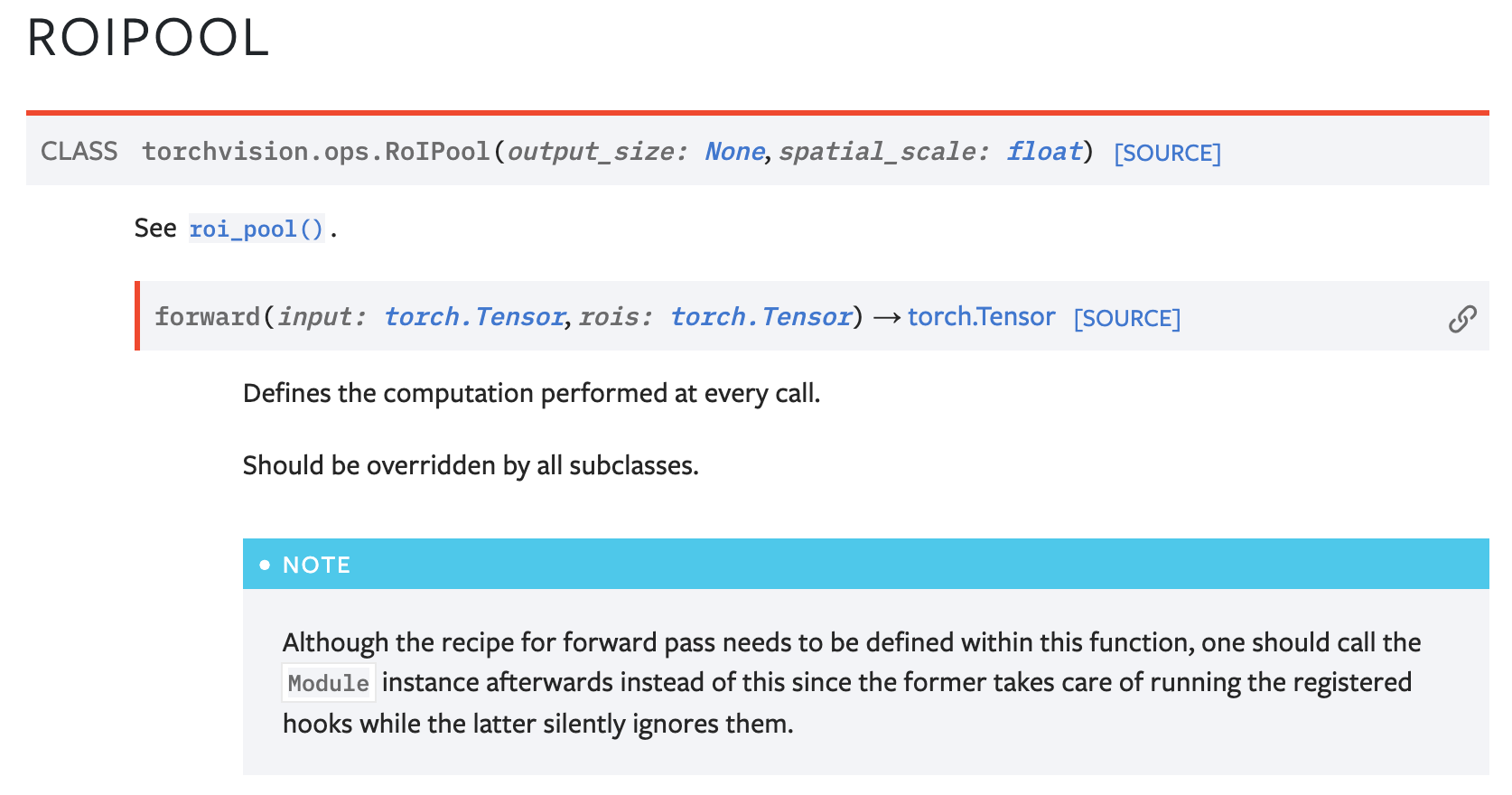
https://pytorch.org/vision/main/generated/torchvision.ops.RoIPool.html 에서 설명하듯이, RoIPool라는 클래스는 output_size와 spatial_scale이 parameter로 들어갑니다.

그리고 forward 에서 roi_pool 이라는 함수를 호출합니다. 즉 필요한 parameters 는 input, rois, output_size, spatial_scale 입니다. 각각은 아래에서 설명을 볼 수 있습니다.
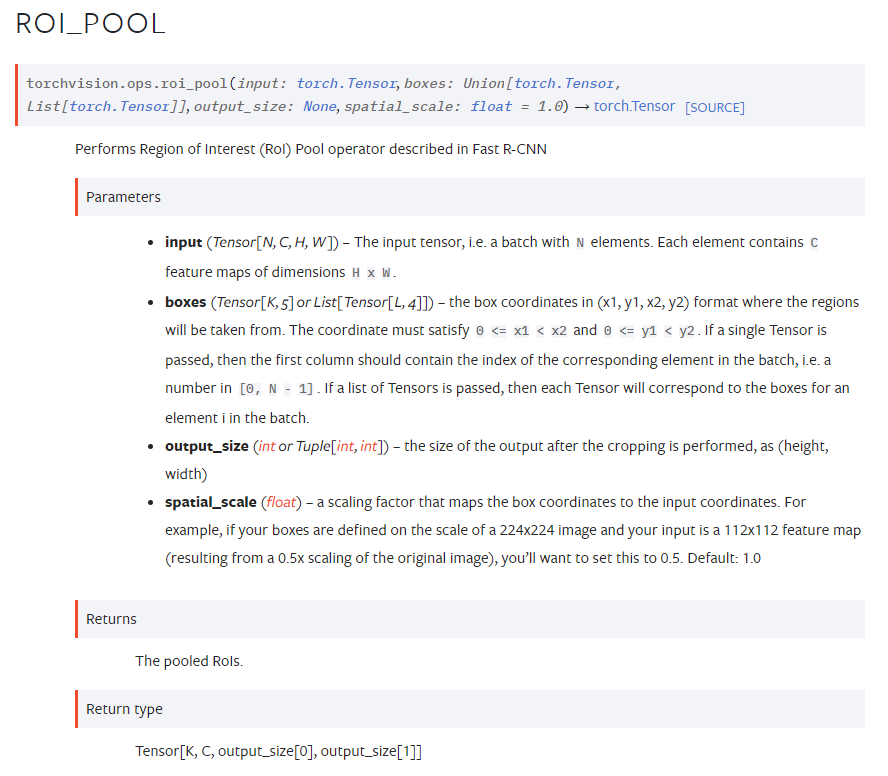
input - N, C, H, W 의 tensor 예를들어 2, 3, 300, 300 의 이미지 일 수도 있고, 2, 512, 60, 60 의 feature 도 가능합니다.
boxes - roi 부분으로 우리가 원하는 영역의 (x1, y1, x2, y2) 의 box들 입니다. 그런데, 2가지 종류의 입력이 가능합니다.
- List of Tensor - [Tensor, Tensor, ... , Tensor] 텐서들의 list
- Tensor[K, 5] - batch 정보가 추가된 [K, 5] shape 의 텐서.
- 예를들어 list_of_tensors = [torch.FloatTensor([[79.8867, 286.8000, 329.7450, 444.0000],
[11.8980, 13.2000, 596.6006, 596.4000]])] 과
roi_tensor = torch.FloatTensor([[0, 79.8867, 286.8000, 329.7450, 444.0000],
[0, 11.8980, 13.2000, 596.6006, 596.4000]]) 는 같은결과 가짐.
output_size - RoI Pool 이후의 (h, w) size
spatial_scale - box coordinate 와 input coordinate의 scale 차이
이미지로 예를 들어 보겠습니다. 다음 이미지는 600 x 600 의 resolution 이고, 사람과 강아지가 object 로써 box들이 쳐져 있습니다. 😁 우리는 이 boxes (region)에 해당하는 부분을 maxpooling을 통해서 같은 크기로 2개의 이미지를 crop 해 올 수 있습니다.
boxes_tensor = [torch.FloatTensor([[79.8867, 286.8000, 329.7450, 444.0000],
[11.8980, 13.2000, 596.6006, 596.4000]])]

아래의 코드는 이미지를 불러오고 600 x 600 으로 resize와 normalize를 하고 boxes를 기준으로 RoI Pool 의 output을 50 x 50 으로 만들어서, [2, 3, 50, 50] 의 shape을 가져오는 코드입니다.
import torch
import numpy as np
import matplotlib.pyplot as plt
from torchvision.ops import RoIPool
from matplotlib.patches import Rectangle
def visualize_tensor(image, bbox=None, object_num=0):
image = image[object_num] #
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
# tensor to img
img_vis = np.array(image.permute(1, 2, 0), np.float32) # C, H, W
img_vis *= std
img_vis += mean
img_vis = np.clip(img_vis, 0, 1)
plt.figure('input')
plt.imshow(img_vis)
if bbox is not None:
bbox = bbox[0]
for i in range(len(bbox)):
x1 = bbox[i][0]
y1 = bbox[i][1]
x2 = bbox[i][2]
y2 = bbox[i][3]
# bounding box
plt.gca().add_patch(Rectangle(xy=(x1, y1),
width=x2 - x1,
height=y2 - y1,
linewidth=1,
edgecolor=(0, 1, 0),
facecolor='none'))
plt.show()
if __name__ == '__main__':
from PIL import Image
import torchvision.transforms as tfs
# 1. load image
image = Image.open('./figures/000001.jpg').convert('RGB')
# 2. transform image
transforms = tfs.Compose([tfs.Resize((600, 600)),
tfs.ToTensor(),
tfs.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
# 3. set image and boxes tensor
image_tensor = transforms(image).unsqueeze(0)
boxes_tensor = [torch.FloatTensor([[79.8867, 286.8000, 329.7450, 444.0000],
[11.8980, 13.2000, 596.6006, 596.4000]])]
boxes_tensor_scale_1 = [box_tensor/600 for box_tensor in boxes_tensor]
# 4. roi pool for image
roi_pool_for_image = RoIPool(output_size=(50, 50), spatial_scale=1.)
roi_pool_for_image_scale_1 = RoIPool(output_size=(50, 50), spatial_scale=600.)
results_roi_for_image = roi_pool_for_image(image_tensor, boxes_tensor)
results_roi_for_image_scale_1 = roi_pool_for_image_scale_1(image_tensor, boxes_tensor_scale_1)
print(results_roi_for_image.size()) # [num_object, 3, 50, 50]
# 5. visualize
visualize_tensor(image_tensor, boxes_tensor)
visualize_tensor(results_roi_for_image, object_num=0)
visualize_tensor(results_roi_for_image, object_num=1)
visualize_tensor(results_roi_for_image_scale_1, object_num=0)
visualize_tensor(results_roi_for_image_scale_1, object_num=1)
# 6. roi pool for feature
roi_pool_for_image = RoIPool(output_size=(7), spatial_scale=1.)
print(roi_pool_for_image(image_tensor, boxes_tensor).size())
결과는 다음과 같습니다. roi 가 원하는 크기로 max pooling 되어서 출력됩니다. 😃😃😃


코드를 위해 voc test 첫 번째 이미지를 첨부하겠습니다. :)
'Object Detection > RCNN Detection' 카테고리의 다른 글
| [Object Detection] Faster R-CNN DETR PAPER처럼 성능높이기(AP-39.0) (1) | 2023.06.27 |
|---|---|
| [Object Detection] Faster R-CNN (NIPS2016) 진행과정 및 코드구현 (0) | 2022.06.01 |
| [Object Detection] Faster R-CNN (NIPS2016) 엄밀한 리뷰 (1) | 2022.04.25 |
| [Object Detection] Fast R-CNN(ICCV2015) 논문리뷰 (5) | 2022.01.05 |
| [Object Detection] R-CNN Follow-Up (0) | 2022.01.04 |




{kind=link}
댓글