
안녕하세요! pulluper입니다 😀😀😀
이번 포스팅은 드디어 Faster RCNN을 분석을 해 보려 합니다.
Faster RCNN은 2016년 NIPS 에 발표되었으며, 그 이후로도 2-stage object detection의 대표로 계속해서 사용되고 있습니다. 그리고 시간이 지남에 따라 속도와 정확성도 많이 발전하였습니다. 이번 포스팅의 목표는 그냥 리뷰보다는 엄밀하게, 각 요소를 이해하고 하나하나 따져보며 Faster-RCNN 을 분석해 보려 합니다. 개인적으로 웬만한 one-stage object detection 들보다 구현과 이해가 어려웠습니다. 그리고 구현을 위한 엄밀한 자료를 만들어 보고 싶어서 이번 포스팅을 시작해 보게 되었습니다. 그렇다면 엄밀하게 분석한 Faster-RCNN 시작해보겠습니다.
paper : https://arxiv.org/pdf/1506.01497.pdf
Introduction
Faster RCNN은 2 stage를 대표하는 object detection입니다. 기본적인 2-stage object 은 첫번째 stage에서 region proposal 을 진행하고, 이후에 두 번째 stage에서 그 region들을 바탕으로 Object detection을 하는 구조입니다. 지금은 one-stage / anchor free / Transformer 등을 이용한 방법들이 많이 나왔지만, 당시에는 아주 빠른 속도와 높은 성능으로 주목받았던 논문입니다. Faster RCNN은 Fast RCNN을 또한 확장한 논문입니다. Fast RCNN도 2-stage object detection으로, region을 먼저 뽑고 그것을 이용해서 detection을 합니다. 다만 region proposal 시 이용하는 방법이 selective search라는 알고리즘입니다. selective search 의 방법이 다소 느리기에, 이를 보완하려고 region proposal 의 단계 자체를 딥러닝으로 inference를 하도록 합니다. 즉 RPN(region proposal network)이라는 네트워크로 region proposal 의 속도를 높이고 이후 방법은 Fast RCNN을 이용합니다.
다음 그림을 봅시다. 2 stage detection 의 매우 추상화된 과정입니다.
먼저 image가 Stage1 을 지나서 proposal들을 만들고, Stage2 에서 cls / reg feature들을 만듭니다.
이후 post processing 을 지나서 box와 class를 얻을 수 있습니다.
Stage1 의 목표는 Region Proposal 입니다. 물리적으로는 있음직한 여러개의 네모영역(proposals)들을 뽑아내는 것 입니다.
Stage2 의 목표는 proposals와 image 로부터 뽑아진 features 로 부터 class, regression 에 대한 features (cls, reg) 를 만드는 것입니다. 노란색 단계를 거친 방법이 Fast RCNN이고, 분홍색 단계를 거친 방법은 Faster RCNN 입니다.
Overview
Faster RCNN은 RPN(Region Proposal Network)부분, Fast RCNN의 부분으로 나눌 수 있습니다.
각각은 Feature extraction 부분에서 baseline network를 공유한다 볼 수 있지만 학습시에 필요한 model, loss, training 방식등이 다르기에 다음과 같이 구현을 위해 분석해야 할 카테고리를 다음과 같이 정리해 보았습니다.
RPN과 Fast RCNN을 다른 loss, model, training 방식으로 학습하고, 통합하여야 하기 때문에 조금 복잡한것 같습니다. Faster RCNN논문은 Fast RCNN보다는 좀더 RPN에 초점이 맞추어져 있어서 구현을 위해 두 알고리즘의 방법을 위와 같은 차례로 분석을 하도록 하겠습니다. 😂😂😂
RPN(Region Proposal Network)
RPN은 이미지를 넣고, 관심있는 영역들을 출력해주는 역할을 하는 Network로 학습을 해야 합니다.
RPN은 Dataset / Model / Loss / Train / Region Proposal 의 목차로 분석 해 보겠습니다.
- RPN-Dataset
paper의 3.3 Implementation Details를 보면, 다음과 같은 언급이 있습니다.
region proposal and object detection networks 은 single scale로 train, test를 했고 re-scale 방법을 사용했다고 합니다. RPN, Fast RCNN의 data에 대한 augmentation은 Fast RCNN 논문과 같이 re-scaling, 그리고 horisontal flip 을 이용했습니다.
Re-scaling 방식은 Fast RCNN에서 다음과 같이 설명합니다.

s를 600 pixel로 사용한다고 합니다. 그리고 이미지의 aspect ratio를 지키면서 가장 긴 길이는 1000으로 제한되며, s는 600보다 줄어들수 있다고 하네요.
이말을 풀어서 알고리즘으로 생각해보면, 다음과 같습니다.
1) 이미지에서 작은 변(s) 와 긴변(l) 을 구한다.
2) s를 600으로 resize 한다. l 에는 (600 / s) 를 곱해주어 aspect ratio를 지킨다.
3) B = l x (600 / s) 라 할때, 만약 B가 1000보다 크면 작은값으로 만든 600에 (1000 / B) 를 곱해주어
600보다 작게 만든다.
4) 그렇지 않다면, s = 600 이고 긴 변은 B로 rescailing을 한다.
이후의 알고리즘들도 이 방법을 쓰는 경우가 많습니다. 예를들어 2020년 ECCV에서 발표된 DETR에서도 resize 함수를 위의 방법처럼 구현하였습니다.
https://github.com/facebookresearch/detr/blob/main/datasets/transforms.py#L76
GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers. Contribute to facebookresearch/detr development by creating an account on GitHub.
github.com
다음을 분석하면 다음과 같습니다. 초록색 comment는 s = 600, l = 1000으로 생각했을때의 주석입니다.
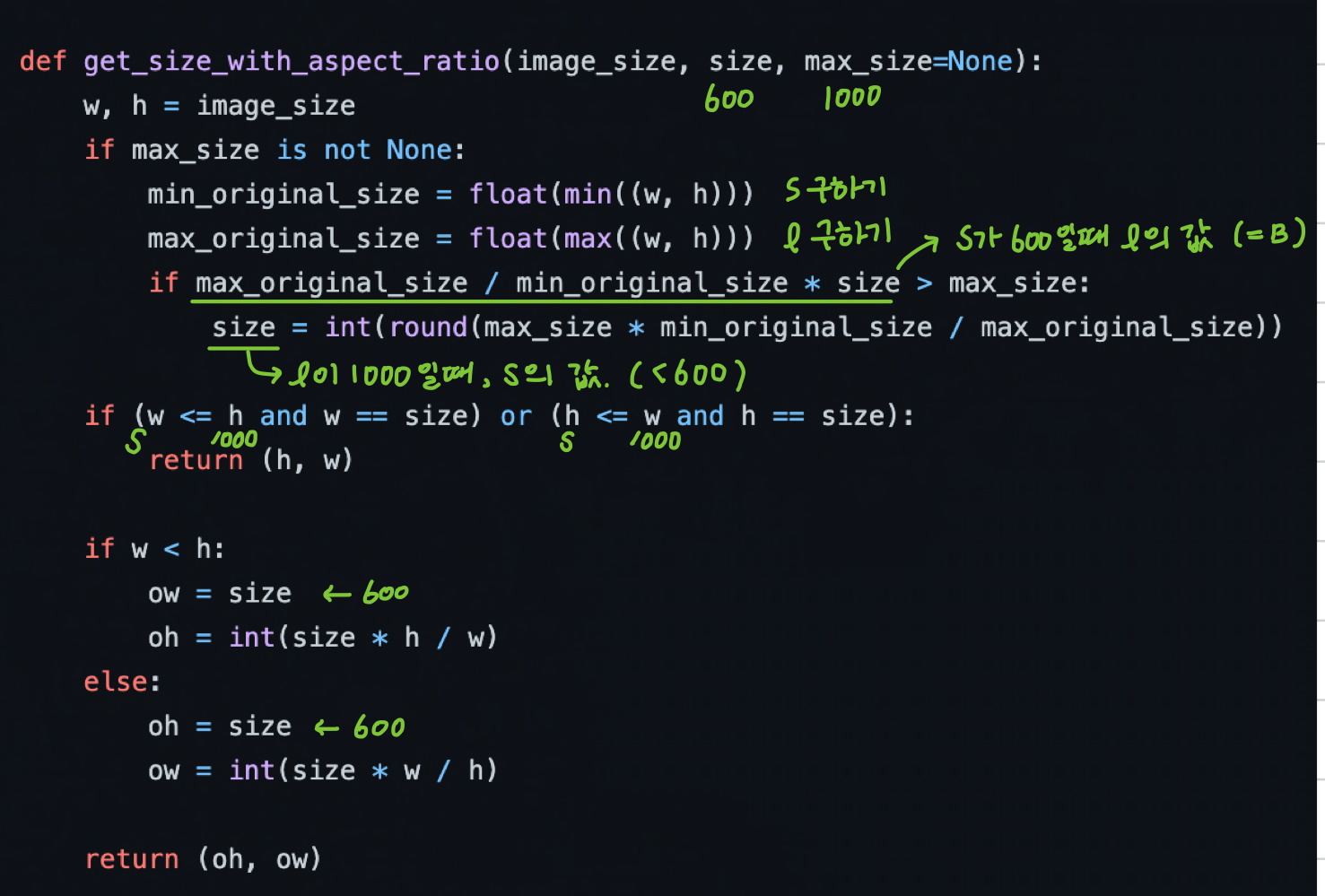
이 방식은 학습할 원본 이미지의 w, h가 모두 같지 않다면, 동일한 W, H를 갖는 입력 이미지를 보장하지 않습니다.
horisontal flip 방식은 이미지와 annotation을 0.5 의 확률로 오른쪽, 왼쪽을 뒤집는 것 입니다.
이후의 Faster RCNN의 version은 더 많은 data augmentation을 이용하지만 처음 version의 논문은 2가지의 augmentation을 사용했습니다. 🤩
- RPN-Model
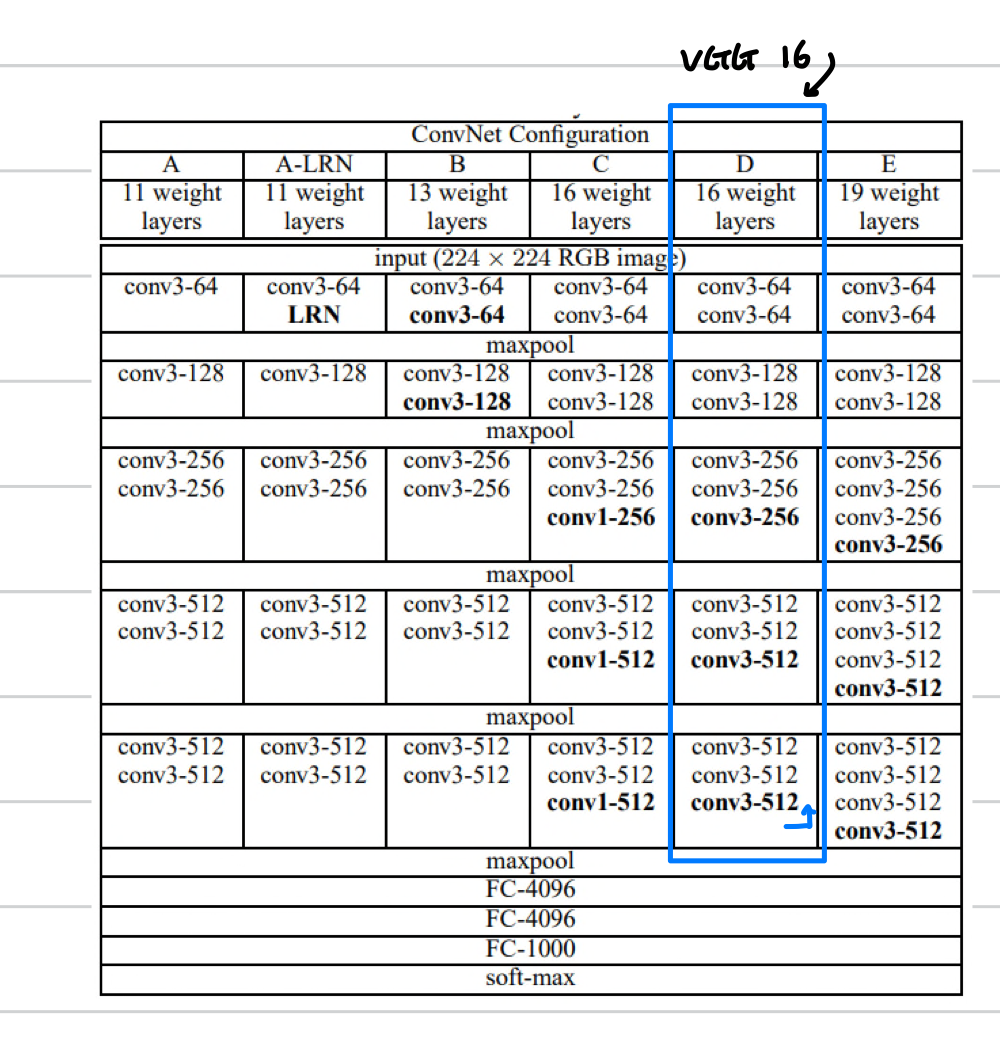
paper에서는 당시에 많이 쓰였던, VGG-16 version을 사용하였습니다.
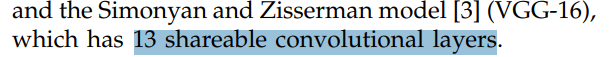

Fast RCNN 논문에서는 VGG의 13개의 layer 를 사용하였고 마지막, pooling layer 는 RoI pooling 으로 이용했다고 합니다.
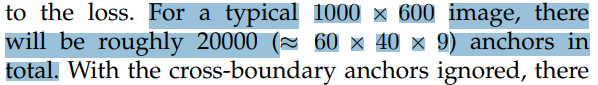
또한 1000 x 600 -> 60 x 40 이 된것으로 보아 stride 는 약 16이 됨을 알 수 있습니다.
그리고 다음과 같은 다른 구현체들을 참고해서 VGG-16에서 마지막의 maxpooling 을 제외한 baseline을 사용한 것으로 알 수 있습니다.
https://github.com/chenyuntc/simple-faster-rcnn-pytorch/blob/master/model/faster_rcnn_vgg16.py
https://github.com/endernewton/tf-faster-rcnn/blob/master/lib/nets/vgg16.py
https://github.com/jwyang/faster-rcnn.pytorch/blob/master/lib/model/faster_rcnn/vgg16.py
이후 RPN은 cls와 reg 의 branch 를 갖는 네트워크를 사용합니다. 논문에서 cls와 reg가 fully-connected layers 라고 언급이 되었지만 이는 자연스럽게 1x1 conv 로 구현이 된다고 서술되어 있습니다. 아래에서 보이는 intermidiate layer 는 3x3 conv 로 구현 할 수 있으며, cls layer 와 reg layer 는 1x1 conv 로 구현가능합니다.
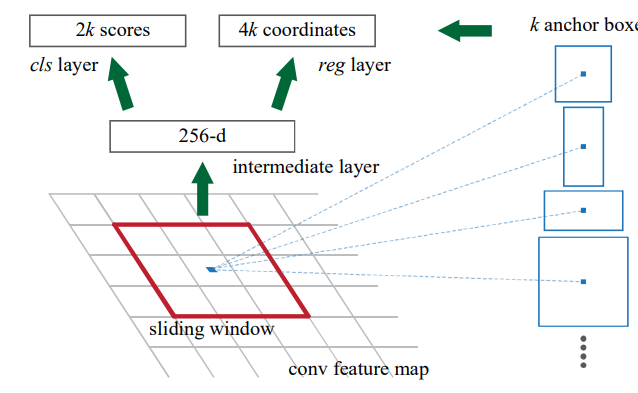
cls, reg 의 branch들은 각각 H x W x 18, H x W x 36의 shape 을 갖는 tensor를 출력합니다. ouput dimension은 anchor의 갯수가 이용되는데, 이는 loss 부분에서 설명하겠습니다. RPN모델의 모습은 다음 그림과 같습니다.
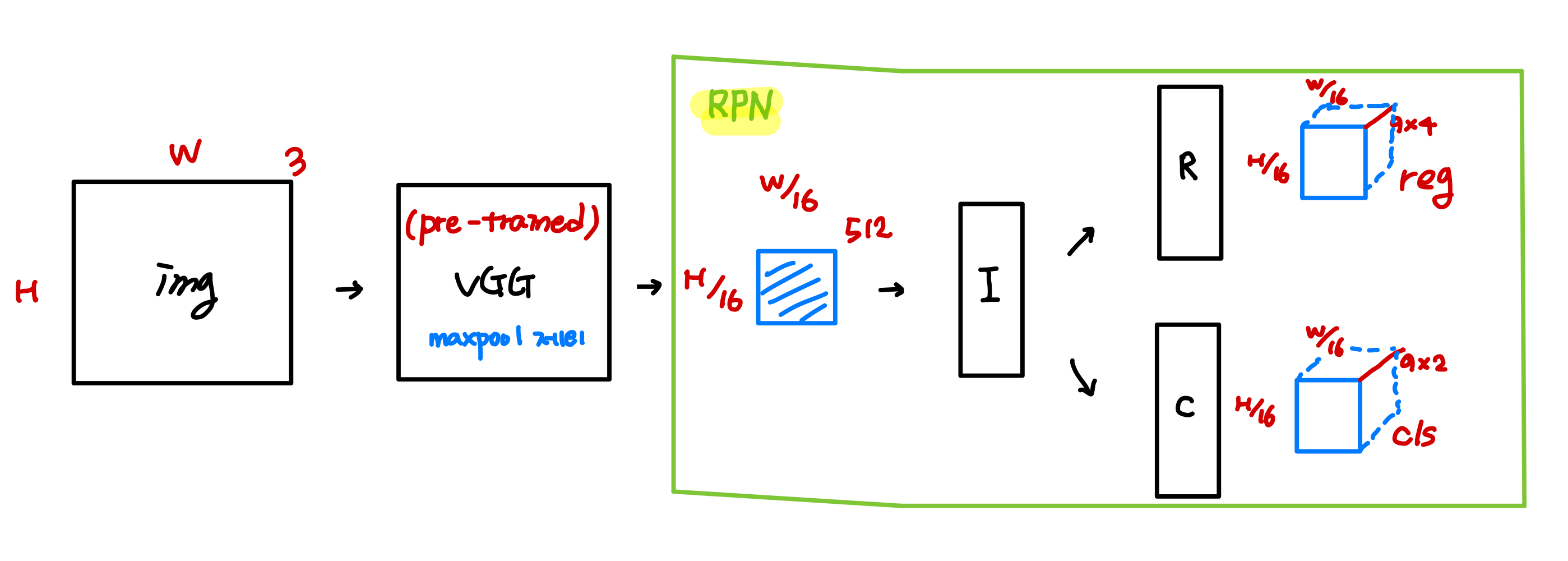
H x W x 3 의 이미지가 입력으로 들어가서 RPN 에 들어가면 H/16 x W/16 x 36 인 reg feature 와 , H/16 x W/16 x 18 인 cls feature 이 출력됩니다. 🤩🤩
- RPN-Loss
Anchor box processing
RPN은 학습을 위해 Anchor box라는 개념을 사용했습니다.
간단히 말하자면, 하나의 feature map에서 여러가지 크기, 모양의 object를 검출하기 위한 미리 정해진 후보 box라고 할 수 있습니다. 자세한 내용은 다음포스팅을 참조하시면 좋을 것 같습니다.
[Object Detection] Anchor Box 설명과 pytorch 구현
안녕하세요 pulluper 입니다 😊 오늘은 object detection에서 많이 쓰이는 anchor box 에 대하여 알아보겠습니다. Anchor 란 "닻"을 의미합니다. 배를 움직이지 않게 하고 배가 어느 위치에 있는지 확인하는
csm-kr.tistory.com
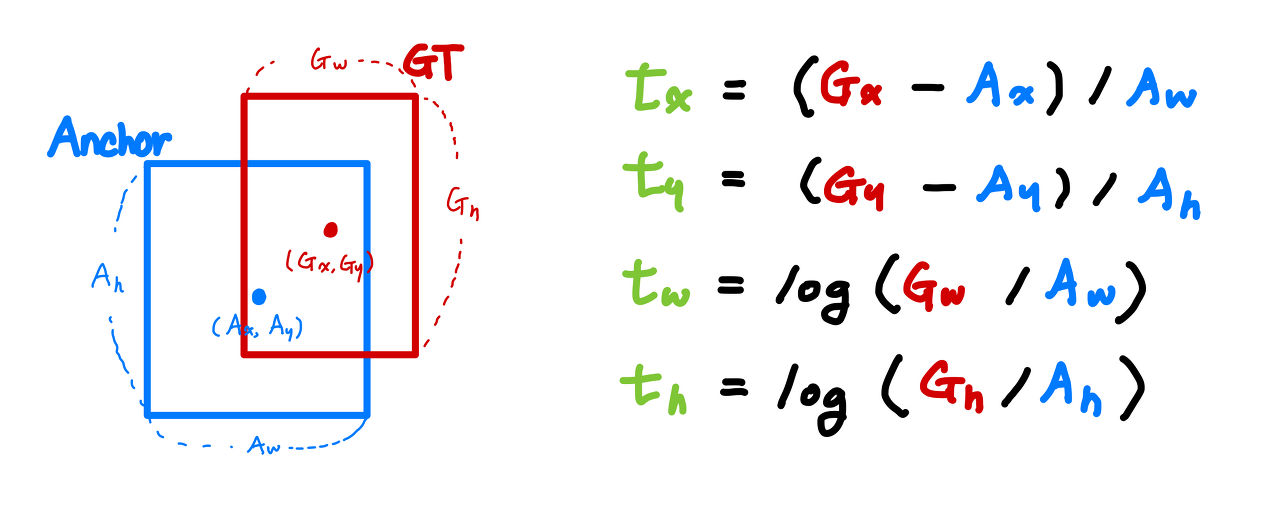
anchor box는 보통 center-coordinates이고 위와 같은 수식으로
1000 x 600 의 이미지에 대한 anchors 는 (20646, 4) 의 shape을 갖습니다.
Assign anchor box
RPN은 물체가 있음직한 부분을 예측하도록 학습이 되어야 합니다. RPN 학습의 정답으로 사용될 anchor를 할당 할 필요가 있습니다.
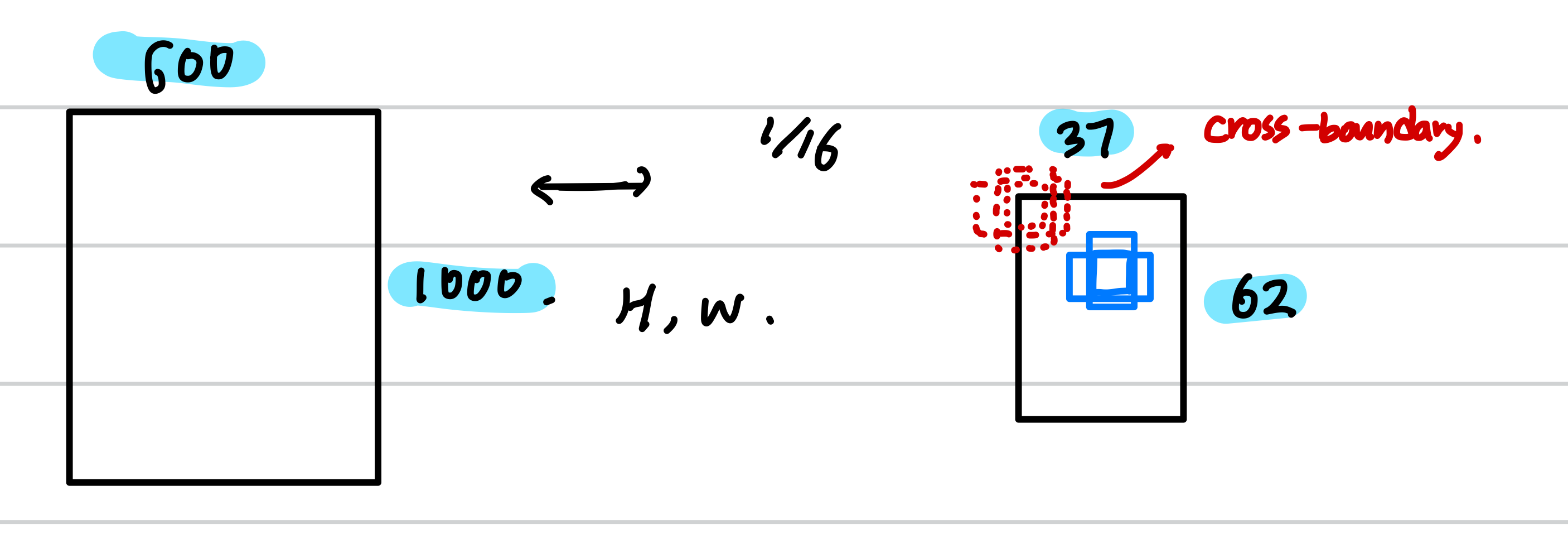
논문의 몇몇 부분에서 실제 학습에 사용되는 anchor에 대한 내용이 3가지 있습니다. 첫번째 implementation details의 다음 부분에서는 cross boundary anchors를 무시한다고 합니다.

이 말인즉슨, 1000 x 600의 이미지가 network를 통과하면, 정확하게 62 x 37 x 9 (=20646) 의 anchor 갯수가 있는데, 이 중에서 다음 그럼과 같이 가장자리를 포함하는 이미지는 제외하겠다는 것 입니다. 이를 통해서 1000 x 600 의 이미지에서는 7652개의 anchor 가 사용됩니다. (논문에서는 대략 6000개라고 함) 이 부분은 오리지널 이미지의 w, h에 따라서 무시되는 anchor 의 갯수가 달라질 수 있습니다. 예를들어 가로로 긴 이미지는 정방형의 이미지보다 더 많은 anchor들이 무시됩니다.
두 번째로 Loss Function 의 부분에서 anchor 할당을 위해서 다음과 같은 방법을 제시하고 있습니다. 1) gt와 iou가 가장 큰 anchor 2) iou가 0.7 이상일 anchor 경우 positive 3) 0.3 이하일 경우는 negative 와 같은 세가지 조건을 만족해야 합니다. 그렇게 되면 GT와 겹치지 않는 많은 수의 anchor 들이 제거가 됩니다.

세 번째는 mini-batch로 사용될때, sampling 을 한다는 점 입니다. 3.1.3 Training RPNs section 에서의 내용을 보면, 하나의 image에서 256개의 anchor 를 sample 을 하여 postive, negative 의 비율을 1:1 로 만들어 학습을 합니다. 기본적으로 positive anchor 는 negative anchor에 비해 수가 적기 때문에 positive anchor 가 128개보다 적으면, negative anchor로 pad 하여서 학습에 사용한다고 합니다.

정리하자면, anchor가 생성이 되고 실제 학습에 사용되는 anchor는, cross-boundary에 겹치지 않으며, 0.7이상이거나 0.3이하인 label이 있는 anchor이면서 실제 256개의 anchor를(pos/neg) sampling으로 뽑은 anchor들 입니다. 결국 이미지 256개의 anchor 가 있고 그것이 loss, 즉 학습에 사용됩니다.
Loss of RPN
network 의 output은 cls 와 reg 입니다. cls [B, 18, H', W'] 이고, reg 는 [B, 36, H', W'] 입니다. reg 는 위에서 다룬 make target 수식으로 인해서
이미지로는 아래와 같습니다.
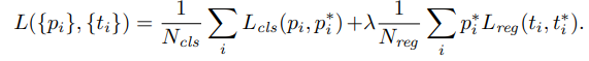
[1000. 600] 의 이미지를 기준으로 각각의 기호의 의미와 shape 은 다음과 같습니다.
-
-
-
-
-
-
-
-
여기서
이 부분은 구현할 때 필요한 기술적인 부분입니다.
nn.BCELoss, nn.SmoothL1Loss 등은 loss 를 생성할 때, 같은 size 의 tensor 를 원하기 때문에 구현상으로는 정답 tensor 와 pred tesnor 의 size를 같게 만들어 주는 것이 좋습니다. 대신에 masking 을 통해서 내가 원하는 (에를들어 256 개의) class label 들만 학습에 적용될 수 있도록 구현되고는 합니다.
- RPN-Train
학습 config 는 다음에 잘 나와 있습니다. 먼저 VGG를 제외한 RPN의 layer는 zero mean Gaussian initialize를 사용합니다. (0, 0.01) 그리고 learning rate는 0.001부터이고, weight decay 는 0.0005, momentum은 0.9 입니다.

그리고 60k의 mini-batches는 lr을 0.001로 , 20k는 lr을 0.0001로 학습을 한다고 합니다. 60k의 mini-batch를 이용한다는 것은 256개의 anchor의 갯수(image당 256개) 에 대하여 약 6만번 돈다는 것 입니다. VOC (2007 + 2012) 기준으로 image의 갯수는 22136 입니다. 그렇다면 약 3 epoch(66408)을 학습하면 66k의 mini-batches를 학습할 수 있고, 추가로 1 epoch을 돌면 22k의 mini-batch를 학습하는 것 입니다.
- Region Proposal
학습을 다 마치고 실제 Region 을 Proposal 하는 부분을 보겠습니다.
RPN의 proposals 은 매우 overlap 이 심합니다. 예를들어 nms를 적용하기 전과 후의 사진을 비교해보면 다음과 같습니다.

그래서 rpn의 output을 기준으로 0.7 IoU 로 nms 를 진행합니다. 그리고 한 이미지당 2000개의 proposals 를 남깁니다. traning 에서는 2000개, testing 에서는 300 개의 rpn 을 사용합니다.

Fast RCNN
네 이번에는 이어서 Fast RCNN에 대하여 다뤄보겠습니다. Fast RCNN 부분의 진행과정은 다음과 같습니다.
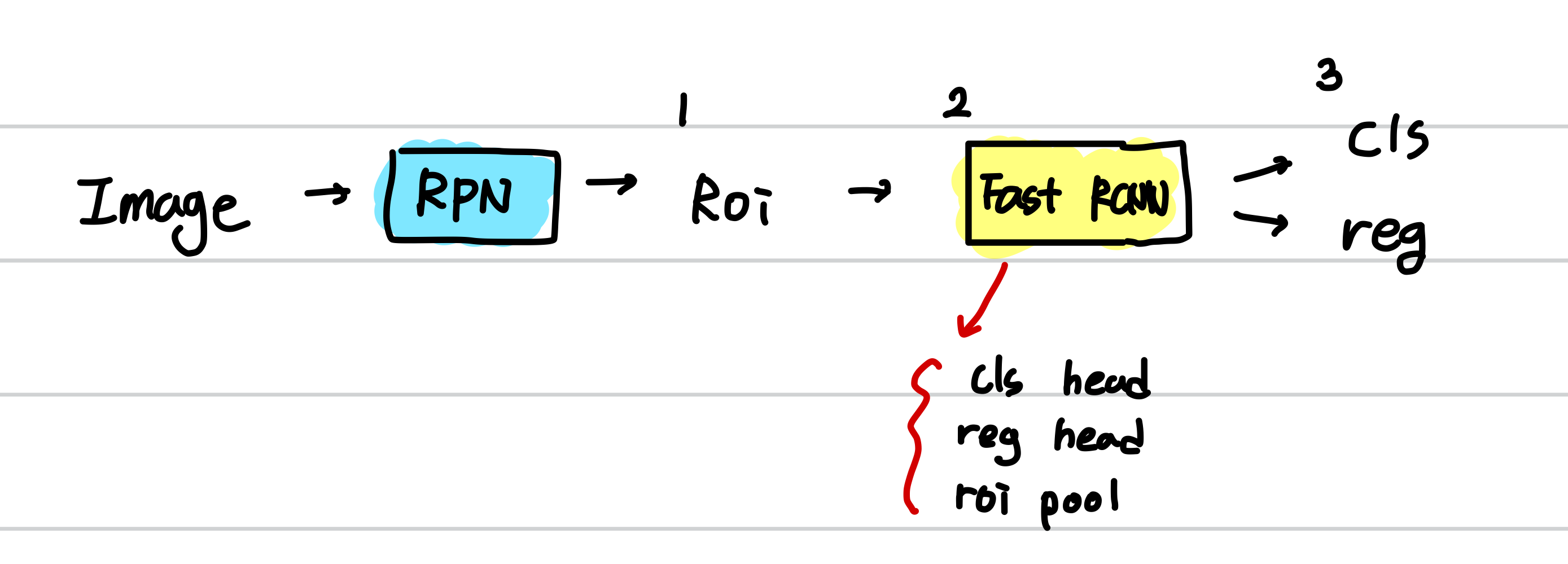
위 그림을 보시면, RPN에서 RPN을 학습시키고, Region Proposal 을 진행하여서 Roi 까지 나오는 부분을 보았습니다.
1. Roi 에 대하여 보면, 최대 2000개의 x1y1x2y2의 bbox 입니다. 즉, [2000, 4] 의 tensor로 표현할 수 있겠습니다. 1에서 2로 넘어갈때, roi에서 128개의 sample 을 뽑아서 sampled roi를 만듭니다 [128, 4]
2. Fast RCNN 모듈에 대하여 보면, 이는 cls head, reg head,와 roi pooling 으로 이루어져 있습니다. 간단하게 feature와 roi에서 sampling 한 sampled roi를 입력으로 받아서, cls, reg의 output을 내 주는 모듈입니다.
3. cls, reg 부분은 fast rcnn의 loss로 들어가서 학습을 하게 됩니다. cls, reg 은 각각 [128, num_classes], [128, num_classes * 4] 의 shape을 가집니다.
요약하자면 Fast RCNN은, 1, 2, 3 번 부분이 어떻게 진행되는지 알고, 마지막에는 3번으로 loss 의 구성을 보시면 됩니다! 따라서 이후의 진행과정은 dataset, model, loss, training, test 으로 알아보겠습니다.
- Fast RCNN Dataset
Fast RCNN 부분의 dataset, augmentation 은 RPN부분과 같습니다. 다만, RPN은 class label 을 사용하지 않고, 학습을 했지만(background, foreground 의 label만 사용) Fast RCNN은 class label 도 사용합니다. 😎
- Fast RCNN Model
Fast RCNN의 model은 다음으로 구성되어 있습니다.
- RoI pooling
- FCs
- FC for cls (cls_head)
- FC for reg (reg_head)
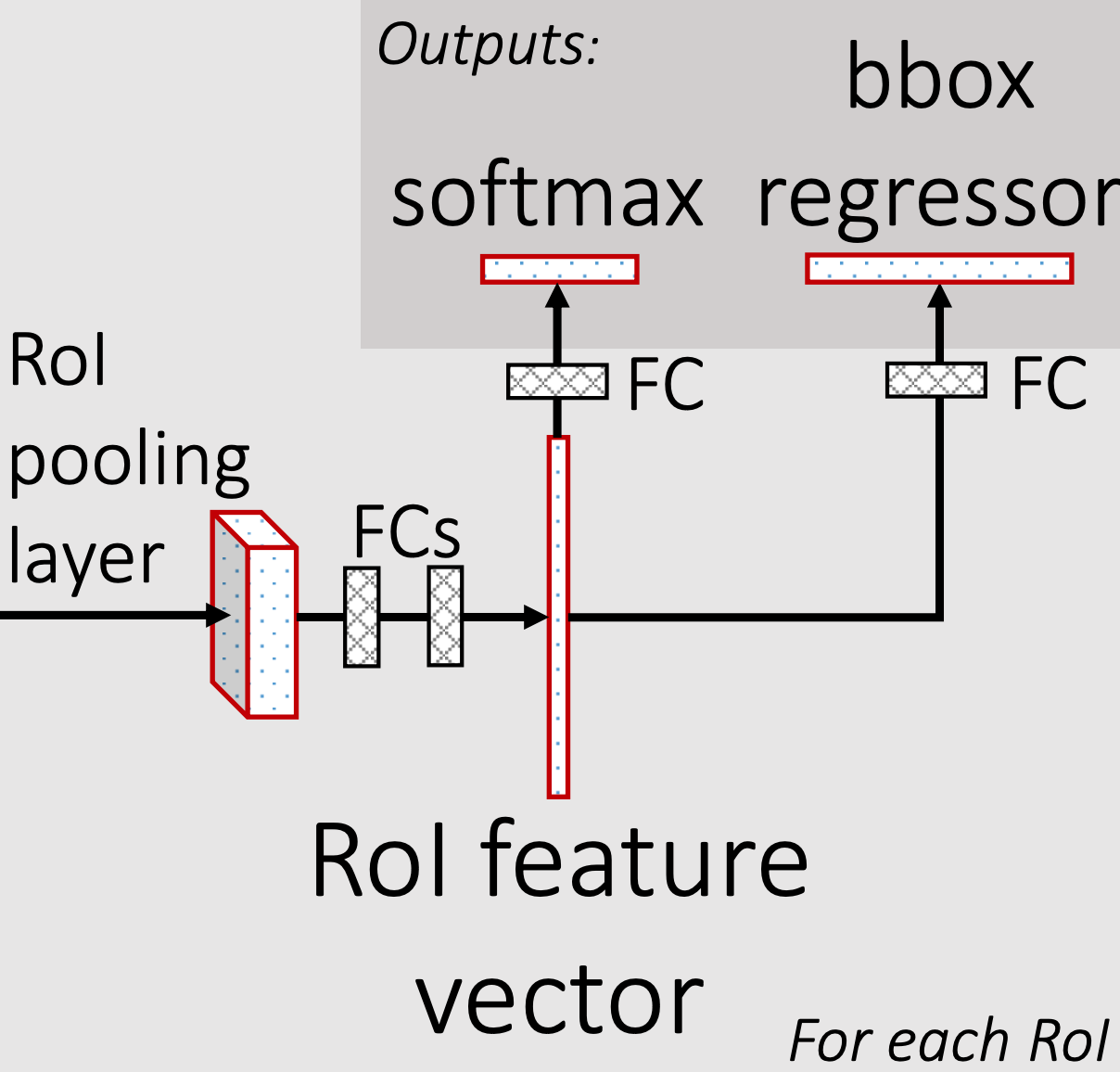
예를 들어 다음과 같이 pytorch code 로 표현가능합니다.
self.roi_pool = RoIPool(output_size=(roi_size, roi_size), spatial_scale=1.)
self.FCs = nn.Sequential(
Linear(in_features=25088, out_features=4096, bias=True),
ReLU(inplace=True),
Linear(in_features=4096, out_features=4096, bias=True),
ReLU(inplace=True))
self.cls_head = nn.Linear(4096, num_classes)
self.reg_head = nn.Linear(4096, num_classes * 4)
- Fast RCNN Loss
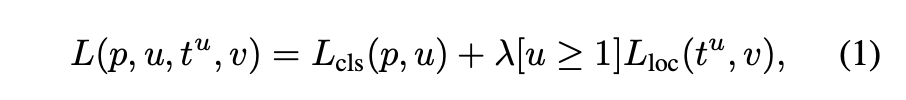
fast rcnn loss 는 다음과 같습니다.
자세한 loss 설명은 Fast RCNN 과 같습니다! 다음을 참조하시면 좋을 것 같습니다.
[Object Detection] Fast R-CNN(ICCV2015) 논문리뷰
안녕하세요 pulluper 입니다. 😀 너무 늦었지만 오늘은 제대로 된 deep learning object detection 의 시작 ICCV2015에서 발표된 Fast R-CNN 을 리뷰 해 보도록 하겠습니다. [paper] 오래 된 논문이니만큼 성능보..
csm-kr.tistory.com
- Faster RCNN Traning
이제 드디어 Traning 부분으로 왔습니다. 논문에서는 여러가지 방법을 제안합니다.
1. Alternating Traning
먼저 RPN을 학습시키고, RPN을 통해 나오는 roi로 Fast RCNN을 번갈아 가며 학습시킵니다. 이는 논문에서 주로 쓰이며, 아래에서 더 설명하겠습니다.
2. Approximate Joint Traning
RPN과, Fast RCNN 의 loss 를 통합시켜서 한번에 학습을 시키는 것 입니다. 이는 approximate 방법으로 비슷한 성능이 나왔고, 학습시간이 줄었다는 장점이 있습니다.
3. Non-approximate Joint Training
위의 방법이 RoI pooling layer 에 대하여 gradient 가 무시되는 문제를 가지고 있는데, 이를 해결하기 위하여 RoI Warping 을 사용한 학습 방법입니다. 그러나 이 방법은 이 paper 의 범위를 벗어난다며 간단히 언급만 합니다.
4-Step Alternating Traning
4-Step Alternating Traning 부분은 다음 그림으로 표현 가능합니다.
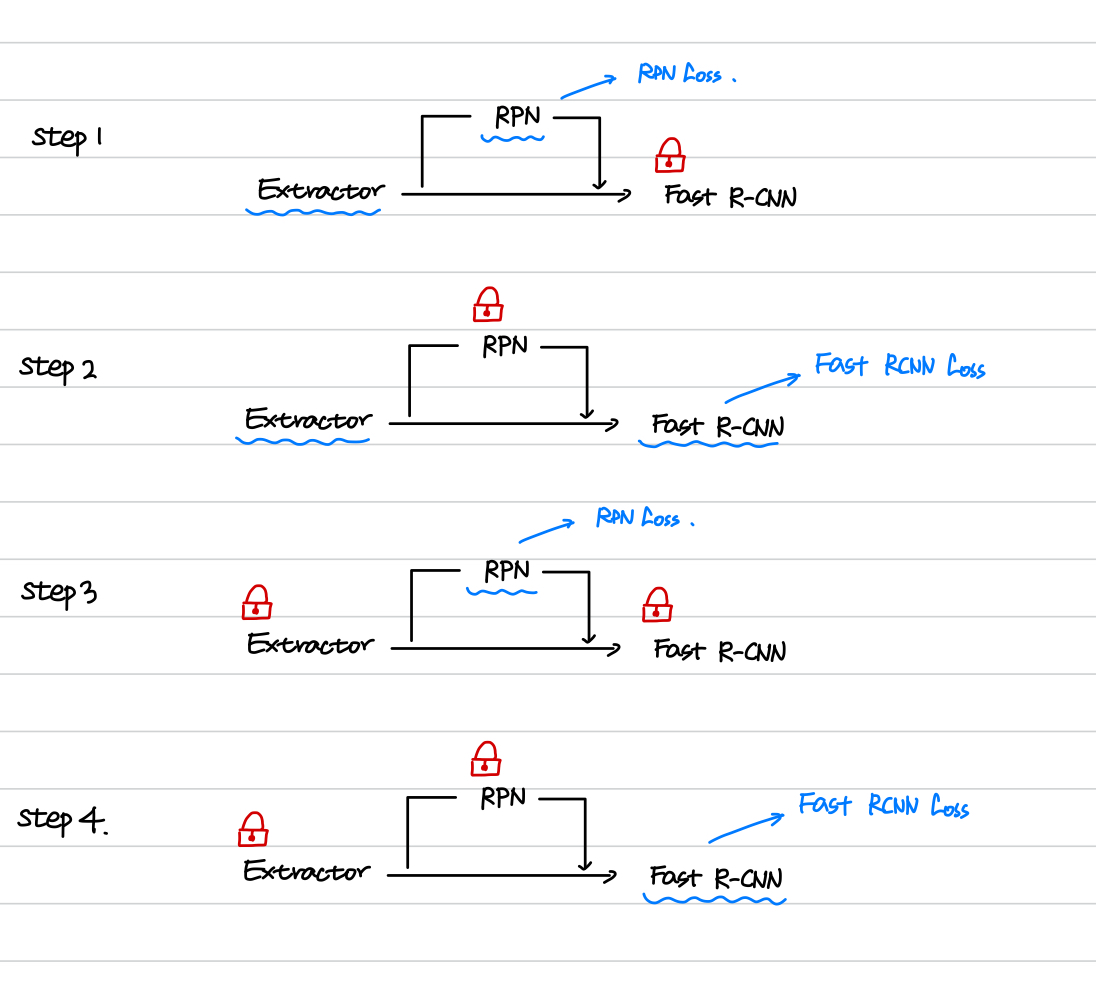
step 1 에서는 Fast R-CNN 부분을 고정시키고, Extractor, RPN을 RPN Loss 로 학습합니다.
step 2 에서는 RPN을 고정시키고 roi를 이용해서 Extractor, Fast RCNN을 Fast RCNN Loss 로 학습합니다.
step 3 에서는 Extractor, Fast RCNN 을 고정시키고 RPN만 RPN Loss 로 학습합니다.
step 4 에서는 Extractor, RPN을 고정시키고 roi를 이용해서 Fast RCNN만 Fast RCNN Loss 로 학습합니다.
학습 부분은 잘 정리된 다음 포스팅을 참고하였습니다. 감사합니다! https://herbwood.tistory.com/10
- Faster RCNN test
드디어 마지막 test 부분이네요! 다른 디텍션들과 마찬가지로,
class score threshould 를 정해주고, nms를 진행합니다 (iou=0.3),
pred reg는 target coord 에서 bbox coord 로 변경시켜 줍니다,
이후 VOC, COCO 등에 대하여 AP를 측정합니다.
결과를 조금 볼까요?
1. VOC 2007 에 관한 mAP : 70% 가 넘어가는 당시 상당히 높은 mAP를 달성하였습니다.
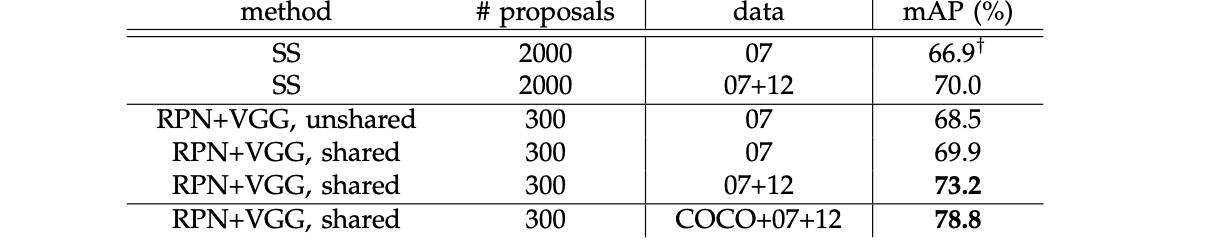
2. mAP of COCO : Fast RCNN 보다 더 높은 21 이상의 mAP를 달성하였습니다.

그리고 자신들의 모듈에 대한 각종 ablation study 도 존재합니다. :) (읽어보시는 것 추천)
마지막으로 qualitative result 를 한번 보고 포스팅을 마치겠습니다.

네 이번 포스팅에서는 다소 길었지만 Faster RCNN에 대하여 다뤄봤습니다. 최근에는 성능도 잘 나오고 아직도 비교에 잘 사용되는 중요한 논문이라고 생각이 되네요. 다음에는 Faster RCNN실제 구현에 관한 포스팅을 해 보겠습니다. 😎😎
질문과 의견은 언제든 환영합니다. 감사합니다. 😀
'Object Detection > RCNN Detection' 카테고리의 다른 글
| [Object Detection] Faster R-CNN DETR PAPER처럼 성능높이기(AP-39.0) (1) | 2023.06.27 |
|---|---|
| [Object Detection] Faster R-CNN (NIPS2016) 진행과정 및 코드구현 (0) | 2022.06.01 |
| [pytorch-torchvision] RoI Pooling 이해하기 및 예제 구현 (0) | 2022.04.22 |
| [Object Detection] Fast R-CNN(ICCV2015) 논문리뷰 (5) | 2022.01.05 |
| [Object Detection] R-CNN Follow-Up (0) | 2022.01.04 |




댓글