
"Introduction"
안녕하세요 pulluper 입니다!
이번에 알아볼 detection은 ICCV2017 에서 발표된 "Focal Loss for Dense Object Detection" 이라는 논문입니다.
이 논문은 RetinaNet 이라는 모델명으로도 잘 알려져 있는데요.
논문의 앞쪽에 이렇게 성능 평가와 속도 그래프를 보여줌으로써 자신들의 detector 가 뛰어나다고 주장하고 있습니다
논문이 나올 당시에 one-stage detection 으로써, two-stage detection들의 성능을 뛰어넘고
state of the art 의 성능을 가지는 facebook team 의 획기적인 논문 이었습니다. :)
"problem definition"
Detection 은 localization 과 classification 의 문제라고 생각을 할 수 있습니다.
아래 출처에서 가져온 그림을 보면 어떤 물체인지 분류 (classification) +
어느 위치에 있는지 파악하는 것 (localization) 으로 이루어져 있습니다.
Deep Learning for Computer Vision
Detection or localization and segmentation Detection or localization is a task that finds an object in an image and localizes the object with a bounding box. This task has many … - Selection from Deep Learning for Computer Vision [Book]
www.oreilly.com
여기서는 classification 에 대한 imbalance 를 문제로 제기합니다.
구체적으로 이 논문에서는 SSD 나 YOLO 등 dense 한 anchor 들을 사용하는
one-stage object detection 에서 foreground 와 background 의 class imbalance 문제를 제기합니다!
즉, YOLOv2 는 416x416 의 이미지에 대하여 845개,
SSD 는 300x300 의 이미지에서 8732 개의 anchor 대하여 prediction 을 합니다.
그런데 몇백~몇천개의 anchor 중에서 object 를 포함하고 있는(foreground) anchor 갯수보다
배경을 담고있는 (background) anchor의 수가 훨씬 더 많을 것 입니다.
그 둘의 비율이 너무 비균형적이라는 것 입니다!

위의 그림에서처럼 약 몇개의 object 를 위하여 엄청나게 많은 anchor 들을 사용하는것을 말합니다.
논문에서는 이러한 foreground ,background class imbalance 는 2가지의 문제를 야기한다고 말합니다.
첫번째는 "training is inefficient as most locations are easy negatives that contribute no useful learning signal" 이고
두번째는 "en masse, the easy negatives can overwhelm training and lead to degenerate models." 라고 합니다.
저는 두 문제가 비슷하다고 생각했는데요!
easy negative (anchor가 배경이라고 판단하는 것) 이 너무 많기 때문에 object 를 찾는 signal 이 비효율적이고
easy negative 에 모델이 압도되어서 성능이 떨어진다고 해석하였습니다.
물론, 이전의 논문들이 이런 문제를 해결하기 위해 사용한 방법도 존재합니다.
YOLOv2 에서는 object 또는 배경인지 판단을 하는 기준을 conf term 과 class score 의 conditional probability 로
정의하여 그 둘의 곱으로 두어서 학습하게 했으며,
SSD 에서는 hard negative mining 방식을 사용해서 negative 중에서는 easy negative 보다 hard negative 에
더 집중 할 수 있도록 heuristic 하게 classification loss 를 만들었습니다.
이 논문에서는 이러한 방식들 보다 더 효과적이고 자연스러운
focal loss를 통해서 이 background foreground class imbalance 를 해결하였다고 주장합니다.
"proposed method"
focal loss
논문에서는 제목에서 볼 수 있듯이 focal loss 라는 loss를 제안합니다.
직관적 판단을 위해 graph 로 나타내기 쉽도록 논문에 나오는 bce 수식을 이용해 보겠습니다.
보통의 Binary Cross Entropy 의 수식은 다음과 같이 나타낼 수 있습니다.
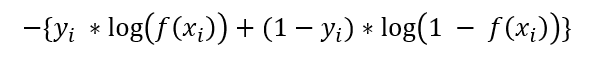
y가 0 또는 1 일때, x 가 [0, 1] 인 -log x의 개형을 갖습니다.
이때, x가 1이면 잘 분류 된 것이고, 0 이면 잘 분류가 안된 것으로써,
학습이 진행 될 수록 loss 값이 작아지는 것이 이상적입니다
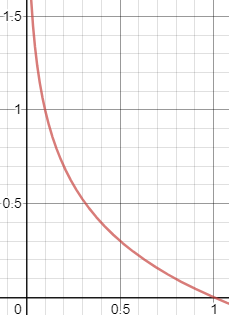
그런데! 덜 분류된 것들에게는 많은 loss 를 주고
잘 분류된 것들에게는 더 작은 loss 를 주어서 쉬운문제 (easy negative) 에 대한 비중을 줄이려는 것이 focal loss 의
아이디어 입니다. 그렇다면 위의 graph 개형에서 좀더 아래로 볼록하면 어떻게 될까요?

파란색 line 이 제안하는 focal loss 인 - (1-x)^2 * log(x) 의 개형인데요.
x의 값이 커질수록 loss 값이 원래의 bce loss (빨간색) 보다 작아집니다. 즉, 쉽게 판단 할 수 있는 sample 에 대해서는
loss 를 조금주어 영향력을 낮춥니다. 반면에 어려운 문제 (x 값이 0 에 매우 가까운)에 대해서는 기존 bce 보다 큰 loss 를 줍니다.
easy negative 에 대한 비중을 줄이면서, hard negative 에 대한 비중 상대적으로 늘리는 classification loss 가 되었습니다!!
논문에서는 이 뿐만 아니라 y가 정답일때와 아닐때 곱해주는 값을 다르게 하는 balanced Cross Entropy 를 더 사용하여
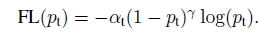
focal loss 를 갖추게 됩니다.
Initialization
이제 focal loss 를 사용해 보려고 하는데, 매우 불안정하고 이상하게 학습이 안됩니다! (loss 가 nan으로 튑니다!)
그런데 initalization을 진행 후 학습을 해 보니, 그제서야 학습이 잘 되는 현상을 볼 수 있었습니다.
제가 생각하기에 이 focal loss 에서 initialization 이 굉장히 중요한 것 같습니다.
chapter 3.3 Class Imbalance and Model initialization 에서 말하기를 binary classification 에서 보통 initialization
을 할때, 두 label 의 확률을 같도록 (0.5) 로 초기화 한다고 합니다.
그러나 이렇게 되면 class imbalance 로 인해서 우세한 class 가 생기기 때문에, 이 논문에서는 prior 라는 개념으로
처음 학습시의 classification 초기화를 마치 rare class 의 것으로 진행하겠다고 합니다. (e.g. 0.01)
저는 이 부분을 이해하기가 조금 어려웠는데 예를들어 설명을 해 보겠습니다.
우리는 어떤 class 에 대하여 binary cross entropy 를 이용하기 위하여 sigmoid 함수를 이용합니다.
그 의미는 "어떤 class" 가 맞을 혹은 틀릴 확률을 나타냅니다. 이 두 확률을 0.01 로 초기화 하고 싶다는 것 입니다!
어떻게 0.01 의 값으로 초기화 할 수 있을까요?
sigmoid 함수는 다음과 같습니다.
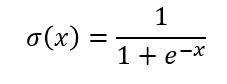
sigmoid 이후의 값을 0.01 로 고정시키면 됩니다. 이것을 계산해 보면,
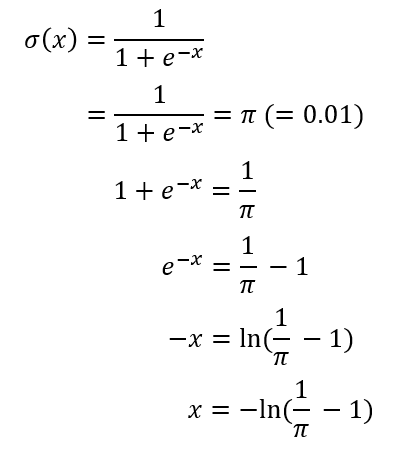
따라서 논문에서 말한것 과같이
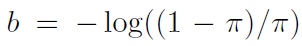
로 bias 를 초기화하고 wieght 는 N(0, 0.01) 에서 sampling 을 하여
초기화를 진행합니다! convolution weight 가 0 에 가깝고 bias 가 b 의 값이 되므로
bias 만 남게되어 초기의 sigmoid 이후의 값을 (0.01) 로 제한 할 수 있습니다!
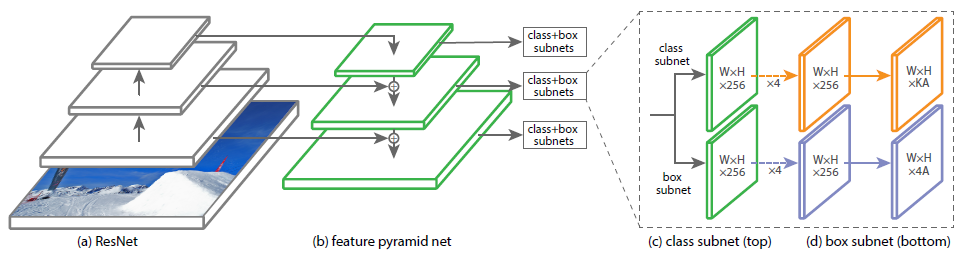
model
이번에는 모델을 알아보겠습니다. backbone 은 resnet 이고, FPN network 를 적용을 하였습니다.
아래 보시는 그림에서 검은색 박스부분에서는 resnet 을 backbone 으로 c3, c4, c5 의 feature를 뽑아냅니다.
각각은 input image 의 1/8, 1/16, 1/32 의 크기를 가지고 channel 수는 512, 1024, 2048 (resnet 50 기준) 입니다.
(클릭하여 확대하시면 잘 볼 수 있습니다 1)
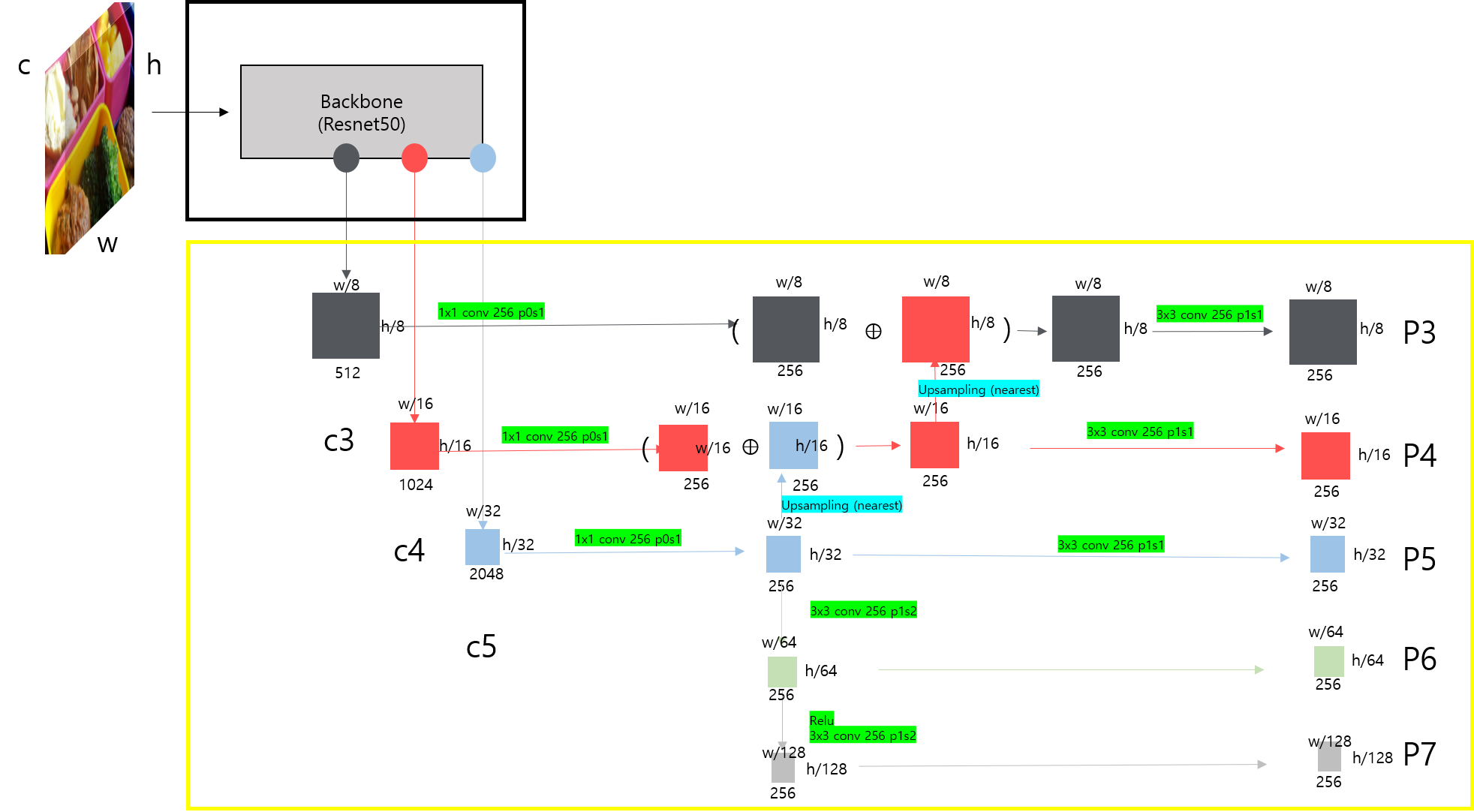
그리고 노란색 박스는 FPN(Feature Pyramid Netwokrs) 부분인데 가장 깊은 feature 인 c5부터 다시 upsampling 을
하고 element-wise 합과 convolution 연산을 하면서 결국에는 p3 ~ p7 까지의 feature 들을 뽑아내는것이 목표입니다.
각각의 사용된 연산들은 highlight 를 해 두었습니다 :)
이렇게 네트워크를 구성하면, top-down pathway 와 lateral connection 을 이용해
multi-scale 을 커버 할 수 있고 효율적인 네트워크가 되어 좋은 성능을 가질 수 있습니다.
논문에서는 network design 이 crucial 하지는 않다고 합니다. resnet 만 이용했을 때 낮은 AP 를 가졌기 때문에 FPN 을
적용하였다고 합니다. FPN 이후의 feature 들은 다음과 같은 subnet 을 공유합니다.
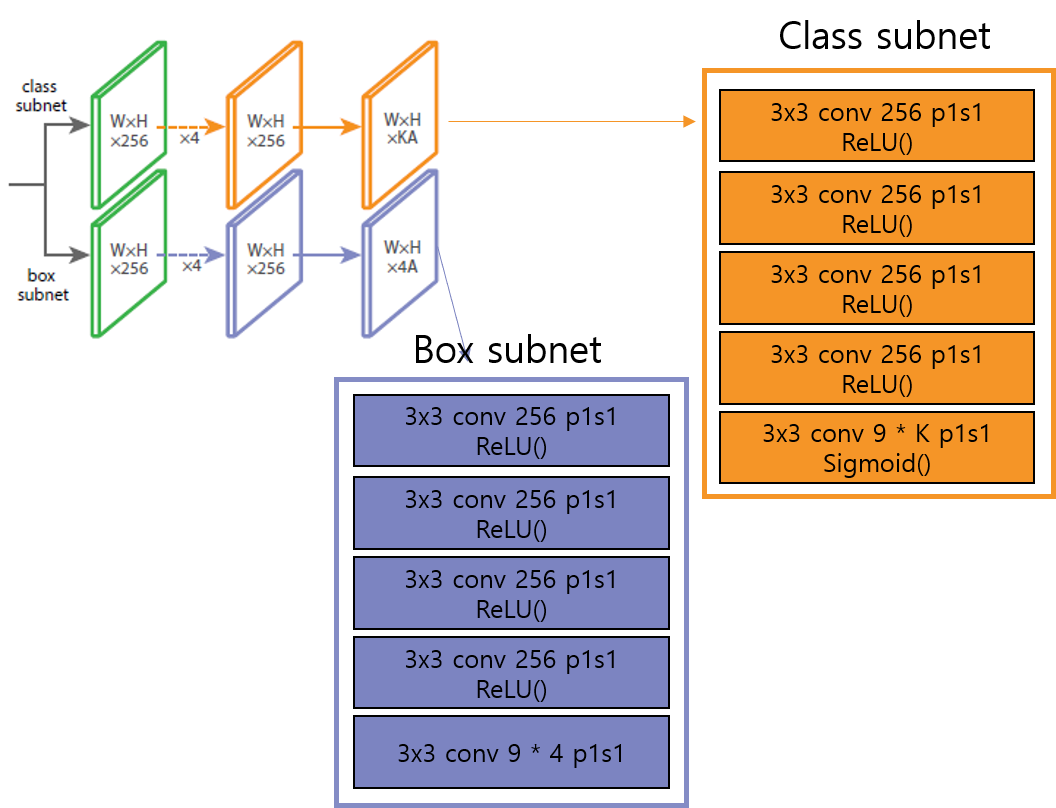
결국 256 channel 을 각각 9 * class 갯수, 9 * 4 로 mapping 합니다. 여기서 9 는 anchor 의 수 입니다.
class subnet은 coco 기준 80 * 9 로, box subnet 은 4 * 9 (cx, cy, w, h) 의
좌표갯수 * anchor 로 channel 이 mapping 됩니다.
이제 마지막으로 p3 ~ p7 을 각각 class subnet 과 box subnet 으로 넣어주면 다음과 같은 output 을 얻게 됩니다.
이때 600 by 600 이미지 기준으로 tensor 를 class, box coordinates 기준으로 정리하면 [B, 67995, classes],
[B, 67995, 4] size 의 tensor 를 네트워크의 output 으로 얻을 수 있습니다.
(클릭하여 확대하시면 잘 볼 수 있습니다 2)

p3 feature map의 1개의 cell에 대하여 9개의 anchor box 가 할당이 되어있고, 각각의 anchor box 는 80, 4
개의 class 와 좌표를 output 으로 가집니다. 따라서 output 은 67995 개의 anchor 기준으로 class 와 좌표를
예측합니다. 매우매우 dense 한 anchor 를 사용했는데요. 따라서 focal loss 의 장점을 사용할 수 있습니다.
모델에서 결과적으로 [B, 3, 600, 600] 의 input 을 넣게 되면 [B, 67995, 80] 과 [B, 67995, 4] 의 output 을 얻게 됩니다.
Anchors
Retina net 에서는 매우 많은 수의 anchor 를 사용하는데, 그 anchor 를 만드는 기준은 다음과 같습니다.
위의 모델에서 p3 ~ p7 의 크기를 고려하여 {32, 64, 128, 256, 512} 들의 제곱을 area 로 갖는 anchor 를 제안합니다.
또한 한 pyramid level 에서 anchor 는 3개의 aspect ratio 를 갖고, 3개의 size 를 더 추가로 갖습니다.
예를 한번 들어보겠습니다. feature map p3 은 75 by 75 의 크기를 갖습니다.

가장 좌측 최상단 p3[0][0] 에 대하여 area 는 32 인 anchor 가
aspect ratio 가 3개이고, {1:2, 1:1, 2:1} , size {2^0, 2^(1/3), 2^(2/3)} 개 이므로 9개의
anchor 를 갖습니다.
전체 anchor 갯수는 75 x 75 x 9 = 50625 개 입니다.
이와같이 p7 까지의 anchor 를 모두 더하면 총 67995 개의 anchor 를 사용합니다.
각 anchor 에는 class 개의 one-hot vector 가 할당되고, 4 개의 vector 가 할당되어
classification target 과 box 의 target 으로 사용됩니다.
이렇게 많은 anchor 들을 학습 시 모두 사용하지 않고, gt 와의 IoU 가 0.5 이상인 친구들만 ground-truth 로
할당합니다. 반면에 IoU 가 [0, 0.4) 인 anchor 들은 background 로 할당이 되며, 그 사이인 [0.4, 0.5) 인
anchor 들은 무시됩니다.
anchor 의 개념은 다음 블로그를 참조하시면 좋을것 같네요 😊
[Object Detection] Anchor Box 설명과 pytorch 구현
안녕하세요 pulluper 입니다 😊 오늘은 object detection에서 많이 쓰이는 anchor box 에 대하여 알아보겠습니다. Anchor 란 "닻"을 의미합니다. 배를 움직이지 않게 하고 배가 어느 위치에 있는지 확인하는
csm-kr.tistory.com
Loss
이제 model 의 output 과 target 간의 loss 를 한번 알아보겠습니다.
크게 loss function 은 focal loss + smooth l1 loss 입니다.
anchor 에서 iou 에 따라서 GT 로 할당되거나 학습에서 무시된다고 하였는데, 정리해보면 다음과 같습니다.
positive mask : iou >= 0.5 # gt_box 와 anchor_box 의 iou 가 높아서 GT 를 할당한다.
ignore mask : 0.4 <= IoU < 0.5 # 학습 시 무시한다.
negative mask : 0 <= iou < 0.4 # classification 의 background 로 할당한다.
여기서 각 mask 는 anchor 를 나타내는 [67995] size의 0 또는 1로 이루어진 mask 라고 생각 해 봅시다.
positive mask 를 만족하는 1의 갯수가 P개, ignore mask 가 I 개, negative mask N 개 있다고 가정하면,
P + I + N 은 67995 가 되어야 합니다.
focal loss 는 하나의 anchor 에 대하여 어떤 class 인지 혹은 background 인지 binary cross entropy 를
이용해서 loss 를 구합니다. 즉, background 와 foreground 모두에 대하여 loss 를 구해야 하기 때문에,
이 mask 들에다 앞에서 설명한 focal loss 를 사용합니다.
classification_loss = (positive mask + negative mask) * FL(pt)
논문에서는 Fast RCNN 에서 제안한 smooth l1 loss 를 사용했다고 합니다.
일단 G 는 ground truth box 이고, A 는 anchor (prior) box, t 는 target 입니다.
아래의 식으로 target 을 만들어 준 후 box regression 은 background 에서는 loss 를 생각하지 않아도 되기 때문에
앞에 positive mask 만 붙여서 loss 를 구성해 줍니다.
tx = (Gx - Ax ) / Aw
ty = (Gy - Ay ) / Ah
tw = log(Gw / Aw)
th = log(Gh / Ah)
regression_loss = (positive mask ) * smooth L1(pred, target)
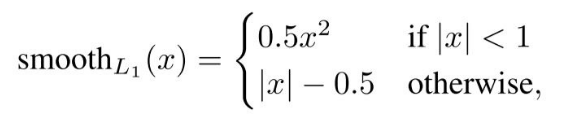
전체 loss 는 두개의 합 입니다. 간략히 다음과 같이 나타 낼 수 있습니다.
loss = classification_loss + regression_loss
Optimization
이번 part 에서는 training 을 위한 optimization 설정을 보겠습니다.
- optimizer : SGD, (weight decay : 1e-4, momentum : 0.9)
- initial learning rate : 1e-2
- batch size : 16
- training step : 90K (90000)
- learning rate decay : 0.1 at 60k and 80k
- weight initialization : FPN 과 같고, back-bone 은 pretrained 한것, RetinaNet subnets 들은 bias b = 0, weight=Gaussian(sigma 0.01), 특히 classification 마지막 subset 은 -log((1 - pi) / pi), pi = 0.01
- data augmentation : random flip 만
Experiments
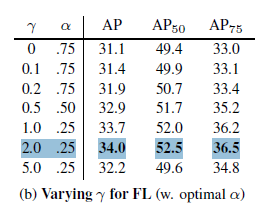
ablation - coco val 2017, 600 by 600 image 에서 lamda 와 alpha 에 대한 ablation study 를 진행하였는데,
각각이 2, 0.25 일때 성능이 가장 좋았습니다.
다음은 속도와 성능의 trade off 에 대한 ablation 입니다.
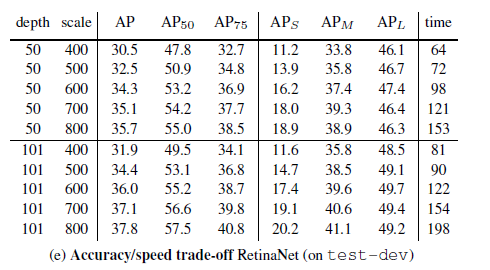
다른 state of the art detector 들과 비교를 했을때, backbone resNeXt-101 로 하고, image size 가 이 800일때,
가장 좋은 성능을 내었습니다.
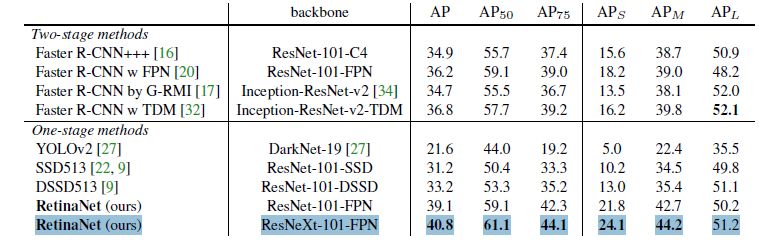
더 많은 실험들과 내용이 논문에 있으니 궁금하신 부분은 확인 부탁드립니다.
classification 에 대한 imbalance 문제를 focal loss 로 효과적으로 풀어간, retinanet 의 리뷰였습니다.
궁금하신 점이나 틀린 부분에 대한 댓글은 언제든지 환영입니다. :)
감사합니다~ 뿅
자세한 디테일을 위한 코드 첨부하겠습니다.
https://github.com/csm-kr/Retinanet_pytorch
GitHub - csm-kr/Retinanet_pytorch
Contribute to csm-kr/Retinanet_pytorch development by creating an account on GitHub.
github.com
'Object Detection > Other Detection' 카테고리의 다른 글
| [Object Detection] FreeAnchor: Learning to Match Anchors for Visual Object Detection (NIPS2019) (0) | 2021.08.22 |
|---|---|
| [Object Detection] SSD 논문리뷰 및 코드구현 (ECCV2016) (6) | 2020.09.08 |


댓글