
안녕하세요 pulluper 입니다 :)
오늘은 eccv 2016 에 발표된 one-stage obejct detection 인 ssd 에 대하여 알아보겠습니다.
SSD: Single Shot MultiBox Detector 는 YOLO 와 함께 real-time one stage object detection의 대표적인 예시이고
현재도 SSD 의 아이디어를 많이 사용하고 있습니다.
위의 논문을 내용을 참고하여 마찬가지로 Introduction, Dataset, Network, Loss, Train, Evaluation
의 순서로 포스팅을 진행하겠습니다. :)
1. Introduction
SSD : Single Shot MultiBox Detector 이라는 제목이 무엇을 의미할까요?
Single Shot 이 의미하는것은 한번 foward 한다는 뜻이고 (1-stage detector), MultiBox 는
이 detector 에서 사용하는 anchor 들이 많다고 하는 것 입니다.
이전에 포스팅 했던 Yolo v2 는 anchor box 가 최종적으로 13 x 13 x 5 = 845 개의
anchor box (prior box) 를 사용했다면 SSD 는 더 많은 anchor box 들을 사용합니다.
이 논문이 주장하는 contribution 은 다음과 같습니다.
- yolo v1 (아직 v2 가 나오지 않은 상황) 보다 빠르고 faster RCNN 만큼 정확하다.
- default bounding boxes (anchors) 마다 cnn filter를 이용하여 score 와 box offset 을 예측하였다.
- 성능을 높이기 위해서 여러 scale 의 feature 들을 이용하였다.
- end to end training 을 하고, 낮은 해상도의 이미지에서도 성능이 높다.
- 여러가지 dataset(PASCAL VOC, COCO, ILSVRC) 에서 sota 와 비빌수 있다.
convolution 이 진행 될 수록, 자연스럽게 feature size (w, h) 의 크기는 줄어들게 됩니다.
예를들어, 3 x 256 x 256 의 input 이 VGG 등을 통과하면 256 x 16 x 16 으로 변한다고 가정하면,
이 줄어든 feature 들은 더 공간적으로 더 넓은 곳을 바라봅니다. (receptive filed 가 크다) - 위 그림의 (c)
그렇게 되면 더 큰 object 를 cover 하는 feature 가 될 수 있습니다.
이 논문의 intuition 은 여러 scale 에서 나온 feature 들을 그 크기에 맞는 anchor 들과 연결하여,
효과적으로 학습한 것이라고 생각합니다.
2. Dataset
맨 첫번째 column 과 맨 마지막의 column 을 비교하여 more data augmentation 의 영향을 알 수 있습니다.
그런데 두 실험의 차이가 무려 8.8 mAP 가 납니다. 논문에서도 data augmentation 이 중요하다고 하고 있습니다!
SSD 논문에서 제안한 data augmentation 은 다음과 같습니다.
- randomly sample patch [0.1, 1]

먼저 들어온 이미지에서 각 w, h 의 크기를 원래 이미지에서 [0.1~1] 비율로 정합니다. (실제 저자의 코드에서는 0.3~1)
로 되어있습니다. 그리고 sampling 한 patch 가 w = 0.5, h = 0.7 로 정해졌다고 가정해 봅시다.
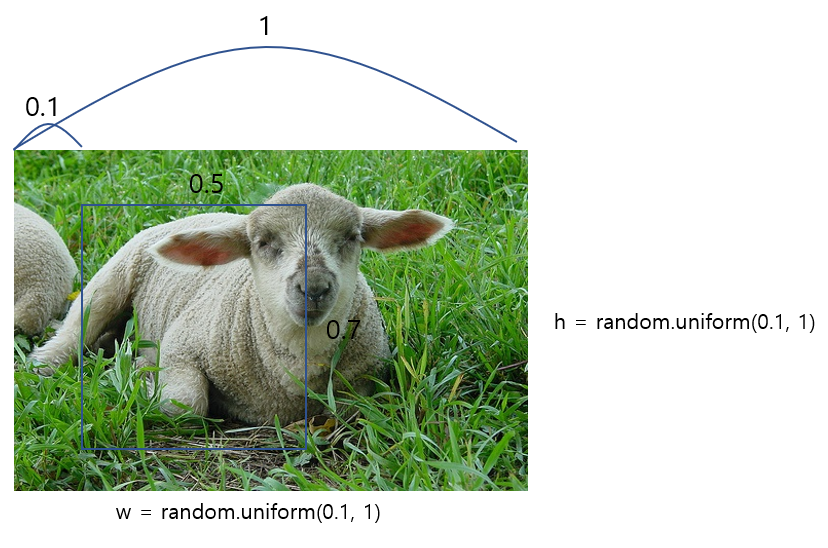
그리고 이 patch 는 aspect ratio 가 0.5 < p < 2 이어야 합니다.
위 예제에서는 0.5 / 0.7 은 1이 약간 안되니까 합격입니다.
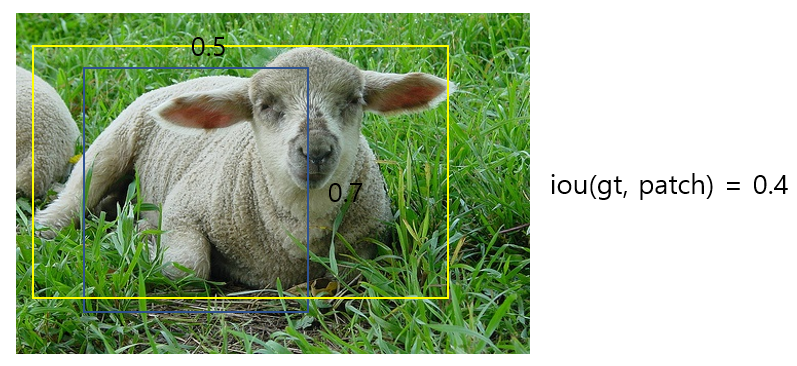
– Sample a patch so that the minimum jaccard overlap with the objects is 0.1, 0.3, 0.5, 0.7, or 0.9.
그리고 이렇게 뽑힌 patch 와 gt(노란색) 사이의 jaccard overlap (IOU) 가 [.1 .3, .5 .7 .9] 중 랜덤으로 뽑힌
값 보다 커야 합니다. iou 의 기준이 0.1 또는 0.3 이 뽑혔다면 아래의 patch 와 gt 와의 iou 인 0.4 가 더 크므로
data 로 쓰이고, 0.5, 0.7, 0.9 라면 다시 patch sampling 을 진행하여 data augmentation 을 합니다.
- horizontally flipped with a probability of 0.5
0.5 비율로 horizontally flipped: 뒤집습니다.

- photo-metric distortions ( Random hue, Contrast, Saturation, 등등)
랜덤 색차 변경 혹은 대비를 주어서 이미지의 색을 바꿉니다.
- zoom in

이미지를 zoom in 합니다. (이 역할을 random crop 이 합니다)
- zoom out

이미지를 zoom out 합니다.
아래의 zoom in 과 zoom out 은 논문 chapter 3.6 에 나오는 내용으로
data augmentation for small object accuracy 라는 제목으로 서술되었습니다.
www.telesens.co/2018/06/28/data-augmentation-in-ssd/
Data Augmentation in SSD (Single Shot Detector) – Telesens
Over the past few days, I have been investigating how SSD (Single Shot Detector), an object detector introduced in the following paper (https://arxiv.org/pdf/1512.02325.pdf) in Dec 2016 that claims to achieve a better mAP than Faster R-CNN at a significant
www.telesens.co
위 블로그를 참고하시면 이해하시는데 더 도움이 됩니다. :)
3. Model
3-1 ) network

논문에서 제안한 SSD 네트워크의 전체 구조는 다음과 같습니다 :)
Base network 로는 VGG16 을 사용하였고, 이후에 Extra Feature Layers 를 추가하였습니다.
먼저 네트워크의 feature 를 뽑는 부분은 다음과 같습니다.

전체적으로 VGG16 네트워크(conv1 ~ conv6, conv7), 그리고 Extra module (conv8~conv11) 로 이루어 졌습니다.
여기서 구현을 위해 주목해야 할 부분이 4가지 입니다
1 번 부분을 보시면, max-pooling 을 이용하고, stride 가 2 인데, 75 x 75 의 feature 가 38 x 38 이 됩니다.
(컨볼루션) 필터 연산의 output 은 보통 다음 식과 같습니다.
output = floor( (I - k + 2p) / s ) + 1 (I : input size, k : filter size, p : padding size, s : stride)
그런데 conv 3_3 이후의 maxpooling 은 floor 를 쓰지 않고, ceil 을 사용하여 숫자를 올림으로 하여 38 x 38 의 feature
를 맞춰줍니다. 즉 다음과 같은 연산을 합니다. output = ceil( (75 - 2 + 0) / 2 ) + 1 = ceil(36.5) + 1 = 37 + 1 = 38
2 번 부분에서는 L2 normalization technique 을 사용하였다고 합니다.
먼저 feature 의 L2 norm 을 구해주고,
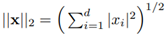
원래의 feature x 를 L2 norm 으로 나눠준 값을 x\{hat} 이라고 합니다.
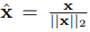
마지막으로 scaling factor \gamma_{i} (voc : 20) 를 곱해줍니다.
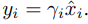
이 방식은 ICLR 2016 의 논문인
ParseNet: Looking Wider to See Better
We present a technique for adding global context to deep convolutional networks for semantic segmentation. The approach is simple, using the average feature for a layer to augment the features at each location. In addition, we study several idiosyncrasies
arxiv.org
에서의 제안을 따르고 있습니다.
논문에 따르면, 학습할 때, scale 을 배워서 더 학습이 stable 해진다고 합니다.
3 번 부분은 그림에서의 conv6, conv7 부분인데요, 여기서는
이미지넷으로 pre-training 된 fc6, fc7 에서 subsampling 을 통해서 conv6, conv7 의 param 을 만들었다고 합니다.
4 번 부분은 atrous convolution 을 사용한 부분입니다.
atrous convolution 은 다음 과 같습니다.
이 convolution 은 더 넓은 시야를 제공합니다.
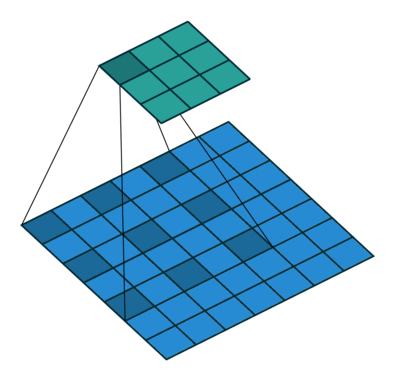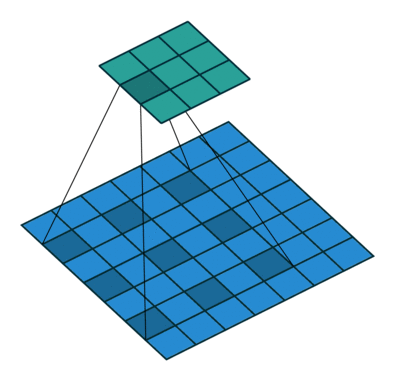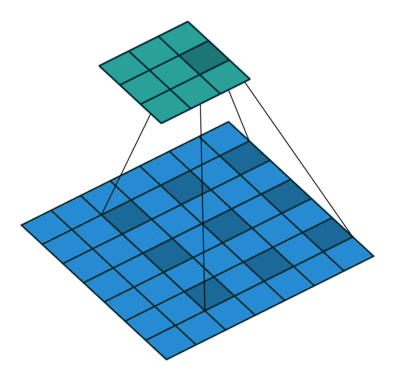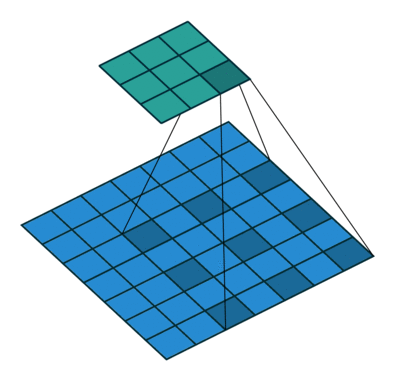
2D convolution using a 3 kernel with a dilation rate of 2 and no padding
reference towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d
An Introduction to different Types of Convolutions in Deep Learning
Let me give you a quick overview of different types of convolutions and what their benefits are. For the sake of simplicity, I’m focussing…
towardsdatascience.com
논문에서는 atrous convolution 을 이용해서 좀더 빠른 계산을 할 수 있었다고 주장합니다.

이렇게 여러가지의 기법들로 network 를 통과 시킨 후에 나온 output 을 conf 와 loc 의 feature 로 한번 더
연산을 합니다. 그 이전에 SSD 에서 사용하는 default boxes(anchor boxes) 에 대하여 알아봅시다.
3-2) default boxes
논문에서는 여러가지의 객체의 scale 을 다루기 위해서 여러개의 dafault boxes (anchors) 를 만들어 이용합니다.
default boxes (anchor boxes) 를 만들때는
scale 과 aspect ratio 가 중요합니다.
aspect ratio 란 한 default box 의 가로와 세로의 비율입니다.

default box 가 object가 있음직한 후보 box 이므로 물체가 가질 수 있는 aspect ratio 를 설정 해 줍니다.
위 사진에서는 빨간 box 는 aspect ratio 가 2, 파란 box 는 0.5 입니다.
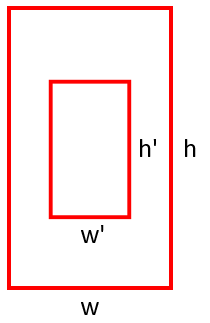
그런데 aspect ratio 만으로는 부족합니다. 위의 그림을 보면 두 빨간 box 는 같은 aspect ratio 를 가지고 있습니다.
각 default box 의 크기를 scale 로 나타냅니다.
scale 은 알고리즘에 따라 다양하게 표현 가능합니다. ( yolo : grid 와의 비율값, SSD : 이미지에 대한 비율값(0-1))
그럼 SSD 에서는 scale 과 aspect ratio 를 어떻게 만드는지 확인 해 봅시다.
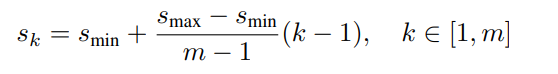
scale 은 위의 식으로부터 계산됩니다. 먼저 용어부터 알아보면,
m : 몇개의 feature map 을 사용할꺼니? (e.g. conv7, conv8_2, conv9_2, conv10_2, conv11_2) 5개!
s_k : scale of k-th layer
s_min : 0.2 (단, 3.1 chapter 의 PASCAL VOC 2007 에서 conv4_3 의 scale 을 0.1 로 setting)
s_max : 0.9 입니다.
SSD 에서는 cnn 을 통과하면서 scale 이 다른 feature 를 사용했기 때문에 이와같이 scale 을 맞춰 주었습니다.
s_0 = 0.1 (# 3.1 chapter 의 PASCAL VOC 2007 에서 conv4_3 의 scale 을 0.1 로 setting)
s_1 = s_min = 0.2 (k=1 이므로 뒤의항 없어짐)
s_2 = s_min + ( (s_max - s_min) (k - 1) ) / (m - 1) = 0.2 + (0.9 - 0.2) * (2 - 1) / (5 - 1) = 0.2 + 0.7 * 1/ 4 = 0.375
s_3 = s_min + ( (s_max - s_min) (k - 1) ) / (m - 1) = 0.2 + (0.9 - 0.2) * (3 - 1) / (5 - 1) = 0.2 + 0.7 * 2 / 4 = 0.55
s_4 = s_min + ( (s_max - s_min) (k - 1) ) / (m - 1) = 0.2 + (0.9 - 0.2) * (4 - 1) / (5 - 1) = 0.2 + 0.7 * 3/ 4 = 0.725
s_5 = s_min + ( (s_max - s_min) (k - 1) ) / (m - 1) = 0.2 + (0.9 - 0.2) * (5 - 1) / (5 - 1) = 0.2 + 0.7 * 4 / 4 = 0.9
따라서 conv4_3 부터 conv11_2 까지 각 [0.1, 0.2, 0.375, 0.55, 0.725, 0.9] 의 scale 을 갖습니다.
aspect ratio 는
conv4_3, conv_10_2, conv_11_2 에서는 [1, 2, 0.5] 를 가지고
conv7, conv8_2, conv9_2 에서는 [1, 2, 3, 0.5, 0.33] 을 가진다고 서술되어 있습니다.
그런데, aspect ratio 가 1 인 경우에
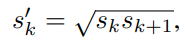
위와 같은 식을 통해서 scale 이 s' 이면서 aspect ratio 가 1 인 하나의 default box 를 추가합니다.
따라서 conv4_3, conv_10_2, conv_11_2 에서는 각 feature 의 pixel 마다 4개,
conv7, conv8_2, conv9_2 에서는 각 feature 의 pixel 마다 6개 의 default box를 사용합니다.
마지막으로 전체의 default box 의 갯수를 알아보면
conv4_3 = 38 x 38 x 4 = 5776
conv7 = 19 x 19 x 6 = 2166
conv8_2 = 10 x 10 x 6 = 600
conv9_2 = 5 x 5 x 6 = 150
conv10_2 = 3 x 3 x 4 = 36
conv11_2 = 1 x 1 x 4 = 4
따라서 총 8732 개의 default boxes 들을 얻을 수 있습니다.
3-3) networks to default boxes
위의 3-1 의 모델에서는 이미지를 넣고 feature 를 뽑아내는 부분까지 알아보았습니다.
그 중에서 conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11_2 feature 들은 각각 anchor 들과 매칭되어
추가적인 conv 를 통해서 loc (위치), conf (클래스) 결과를 출력합니다.
loc 는 [x, y, w, h] 로 4 channel 로 맵핑되고, conf 는 클래스 갯수( voc : 20 + 1(background) ) 로 맵핑됩니다.

총 [B, 8732, 4] 의 loc 와 [B, 8732, 21] 의 conf 를 갖추게 됩니다. (B : batch size)
4. LOSS
Loss 의 기본 개념은 network 가 prediction 한 값과 정답 ground truth 의 차이를 뜻하죠? 그리고 이것을 줄이는
parameter 를 찾는게 우리가 원하는 것입니다. detection 의 경우에는 gt 가 bbox 와 (x1, y1, x2, x2) , class ("car")
로 주어지는데 위에서 보았듯이 network 의 출력은 [B, 8732, 4] ,[B, 8732, 21] 처럼 생겼습니다.
그래서 실제 구현에서는 loss 에 들어갈 수 있도록 변형 해 주어야하고 이것을 encoding 이라고 부르기도 합니다.
그 방법은 "gt 와 anchor 의 iou(intersection of union)가 높은 anchor 들만 loss 에 이용한다"는 것 입니다.
SSD 에서는 iou 가 0.5 가 넘는 아이들만 positive anchor 로 설정하였습니다.
참고로 anchor 는 논문에서의 default boxes 와 같습니다.
예를 들어보면, 파란 box 는 anchor box 입니다.(8732개) 그리고 빨간 box 는 gt 입니다(1개).
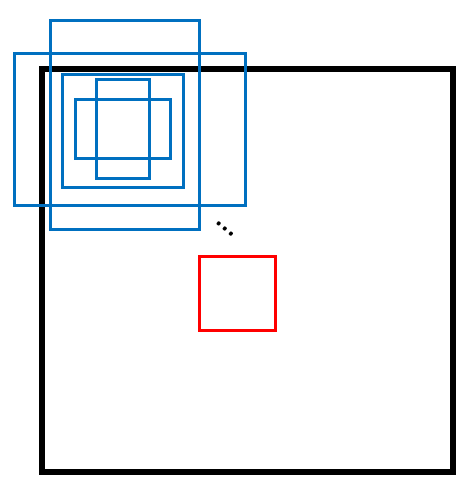
그렇다면 전체 8732 개의 anchor 와 gt 의 iou 를 계산하여 0.5 이상인 부분을 loss 에 이용하고
이는 (x_ij)^p 로 표현합니다.

그리고 두번째 기준은 위 논문에서 sum_i (x_ij^p) >= 1 을 만족해야 하므로, 한 object 에 대해서 적어도 하나의 anchor
는 mapping 이 되어야 한다는 것으로 해석 할 수 있습니다.
그렇다면 iou 가 0.5 가 안되는 상황이라도 한 object 와의 iou 가 가장 큰 anchor 의 x_ij 가 1 이 될 수 있습니다.
이것이 matching strategy 입니다.
이제 loss function 을 알아봅시다.
total loss
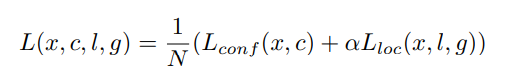
x 는 matching strategy 이고,
c 는 predicted conf (class) 즉, [B, 8732, 21] 의 tensor 이고,
l 은 predicted location (box) [B, 8732, 4] 의 tensor 입니다.
g 는 ground truth box 입니다. 실제 연산시에는 g^ 이 쓰이는데 이는 anchor box (d) 와의 연산으로 만들어 집니다.
또한 전체 loss function 은 L conf 와 L loc 로 나뉘어져 있습니다.
loc loss
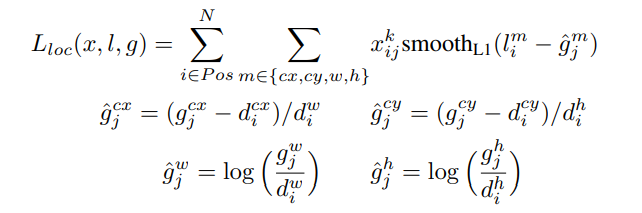
loss loc 를 보면, 모든 positive anchor 에 대하여 각 match 되는 gt에 대해서만 cx, cy, w, h 에 대하여 smooth l1
loss 를 사용합니다.
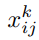
는 matching strategy 를 뜻하고,
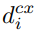
에서의 d 는 anchor boxes(default boxes) 를 뜻합니다.
g^ 은 한마디로 anchor box 를 통해 변환된 gt 라고 생각하시면 됩니다.
그래서 predicted box 인 l 과 변환된 gt 인 g^ 사이의 각 {cx, cy, w, h} 요소간의 smooth l1 를 사용합니다.
cls loss

conf loss 의 앞의 항은 matching strategy 만족하는 positive anchor 에 대하여, cross-entropy 를 사용하는 것이고,
뒤의항은 negative anchor 에 관하여 softmax 결과값이 높은 feature 들을 positive anchor 갯수의 3 배 만큼 뽑아서
(hard negative mining 방식) cross-entropy 를 진행합니다.
5. TRAIN
- inital learning rate : 1e-3
- optimizer : SGD, momentum : 0.9, weigt decay : 5e-4
- learning rate decay : 1e-3 for 40k iters, 10 k 1e-4, 10k 1e-5 (pascal voc)
6. Evaluation
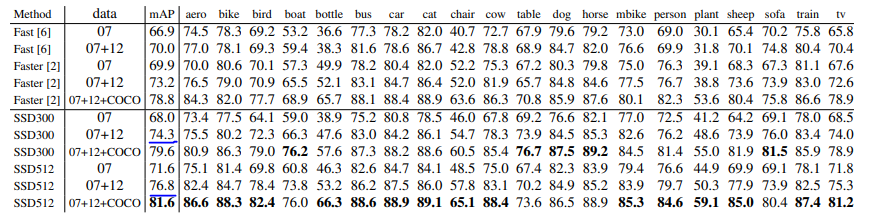
pascal voc 2007 test
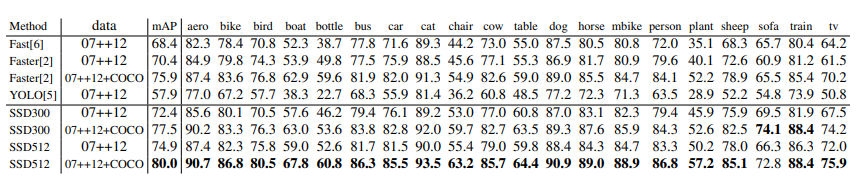
pascal voc 2012 test
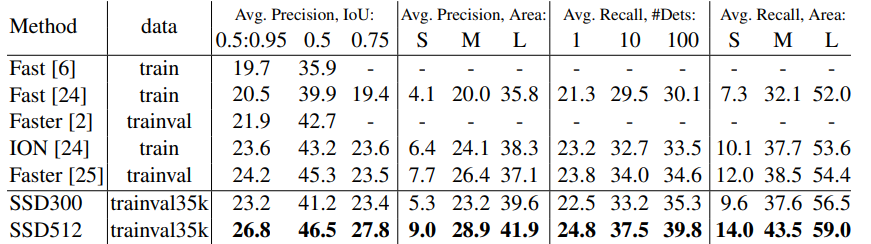
ms coco test-dev2015
fps for pascal voc 2007 test
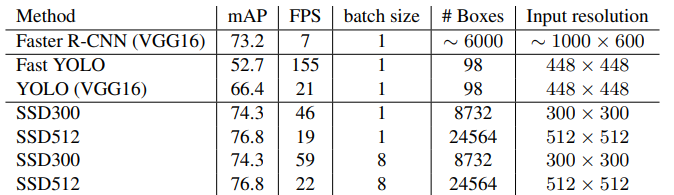
각 dataset 마다 faster rcnn 과 비슷하거나 높은 성능을 내면서 훨씬 빠른 속도를 보여주고 있습니다.
multiple output performance

너무 많은 output 을 쓰기보다는 적당하게 쓰는게 좋다고 주장하고 있습니다.
Qualitative results

네 지금까지 SSD 에 대하여 알아보았는데요.
여기서 사용된 anchor 의 개념이나 multiple feature 등은 이후 나온 detection 들 (retina net, dssd, ...등) 에게
많은 영향을 끼쳤습니다.
궁금하신 점이나 틀린점 있다면 댓글 부탁드립니다.
감사합니다 뿅!
Implementation
다음은 필자가 구현한 실제 코드입니다. 😎
↓ 구현 코드 ↓
https://github.com/csm-kr/ssd_pytorch
GitHub - csm-kr/ssd_pytorch: re-implementation of SSD (ECCV2016)
:blossom: re-implementation of SSD (ECCV2016). Contribute to csm-kr/ssd_pytorch development by creating an account on GitHub.
github.com
'Object Detection > Other Detection' 카테고리의 다른 글
| [Object Detection] FreeAnchor: Learning to Match Anchors for Visual Object Detection (NIPS2019) (0) | 2021.08.22 |
|---|---|
| [Object Detection] RetinaNet (Focal Loss) 논문리뷰 및 코드구현(ICCV2017) (5) | 2020.12.30 |


댓글