컴퓨터 비전 실험을 하다보면 아이디어가 떠올라서 가장 처음에는 MNIST나 CIFAR10/100과 같은 작은 데이터셋에서 실험을 수행하게 된다. 이후 작은데이터셋에서의 검증이 끝나면 어느정도 규모가 있는 데이터셋에서 실험을 하고 싶다. 이때 만만한 데이터셋이 ImageNet 1K이다.
학습데이터 : 1281167개, 검증데이터 : 50000개가 존재한다.
그런데, hugginngface 에서 쉽게 받을수 있는 방법이 있어서 소개하려한다.
이미지넷은 아주 예전 포스팅에서 한번 다뤘었다.
ILSVRC(Imagenet classification)validation set torchvision 으로 성능평가하기
안녕하세요! "pulluper" 입니다. 이번 포스팅에서 다룰 주제는 ILSVRC(Imagenet) 에 대한 설명과 torchvision library 를 통한 Imagenet validation set 성능평가 입니다. Detection 혹은 Network 관련 논문을 4개정도 뽑아
csm-kr.tistory.com
잘 따라하면 받을수 있도록 블로그를 작성하려 한다. 😘
1) Agree and access repository 하기
hugging face imagenet-1k 에 접속하자. 그리고 로그인한다.
https://huggingface.co/datasets/ILSVRC/imagenet-1k/tree/main/data
ILSVRC/imagenet-1k at main
This repository is publicly accessible, but you have to accept the conditions to access its files and content. By clicking on “Access repository” below, you also agree to ImageNet Terms of Access: [RESEARCHER_FULLNAME] (the "Researcher") has requested
huggingface.co
그러면 다음과 같은 화면이 뜰텐데. "Expand to review and access" 를 누르고 "Agree and access repository" 를 클릭한다.
(이거 안하면 아래 과정을 진행해도 안된다.)

이제 다음과 같이 files and versions 가 보인다.
2) Access Tokens 받기
오른쪽 위의 내 계정 누르고, Access Tokens 로 들어간다.
이후 Create new token 누른다. 필자는 Repositories 와 Inference 만 모두 체크 하였다.
다 만들면 다음과 같이 토큰 보여주는데, 꼭 저장해야한다. 다시 볼수 없다.
3) python script 로 데이터 다운받기
3-1 필요 라이브러리 받기
원하는 env 가상환경 python 에 다음을 받는다.
pip install datasets
pip install --upgrade huggingface_hub
3-2 데이터 받는 스크립트 실행
HfFolder.save_token("여기내부") : "여기내부" 에 자신의 token 을 넣는다.
from datasets import load_dataset
from huggingface_hub.hf_api import HfFolder
HfFolder.save_token("your_token_tktktktkektkektk")
# If the dataset is gated/private, make sure you have run huggingface-cli login
dataset = load_dataset("imagenet-1k")
3-3 혹시 SSL: CERTIFICATE_VERIFY_FAILED 에러가 날때는 다음을 변경해준다.
(Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1007)')))")))
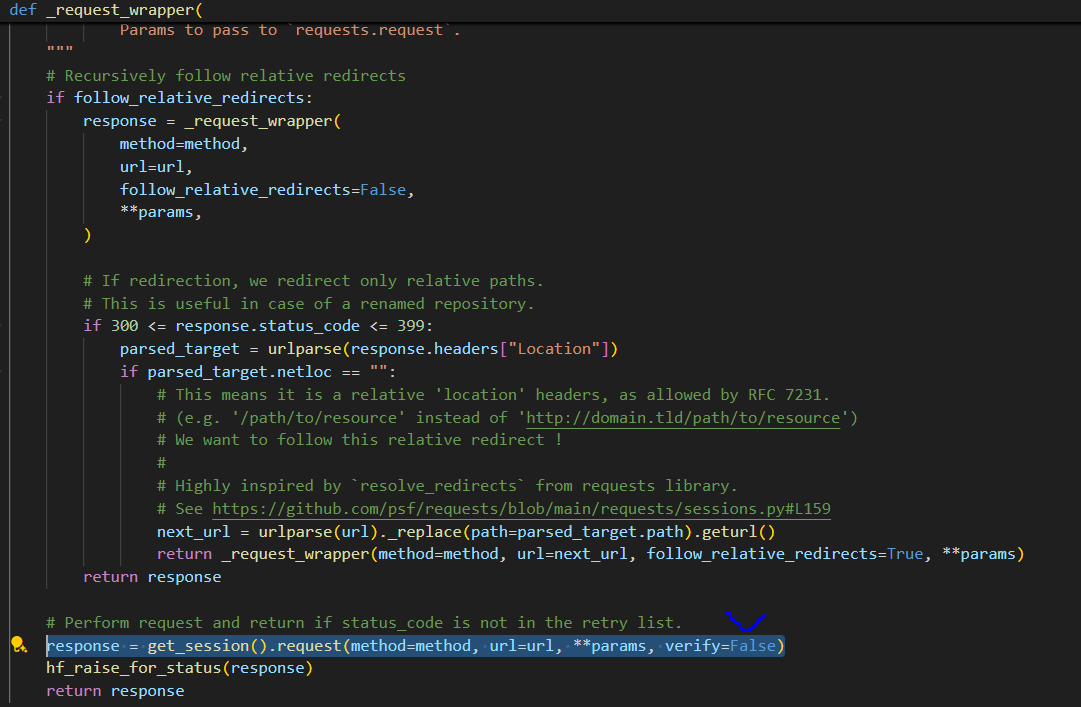
C:\Users\{유저이름}\AppData\Local\anaconda3\envs\{가상환경이름}\Lib\site-packages\huggingface_hub\ file_download.py 으로 가보잣.
_request_wrapper 함수안의 response 부분 verify=False 추가
3-4 다운로드 성공 (다운로드가 꽤 빨리 된다(1h))
주의할점은 150기가정도의 여유가 있어야 받아짐 받아지는 곳은 다음 구간이다.
C:\Users\{유저이름}\.cache\huggingface\datasets\imagenet-1k

필자는 용량이슈 때문에 다음으로 옮김 : 확실히 로딩하는데 더걸린다 (20분정도?)
D:\data\.cache\huggingface\datasets\imagenet-1k
** 옮기면 아래 코드에서 load_dataset 함수에서 cache_dir 를 변경해 주어야 한다 **
다운이 다 받아진 후
C:\Users\ {유저이름} \.cache\huggingface\hub\datasets--imagenet1k\snapshots\~\data 는 지워도 무방 (용량만 차지)
4) 다운로드 후 데이터셋 이용
다음 코드를 이용하면 다운로드 후 이미지 출력까지의 확인을 할 수 있다.
import cv2
from datasets import load_dataset
from torchvision import transforms
from huggingface_hub.hf_api import HfFolder
train_transform = transforms.Compose([
# transforms.RandomResizedCrop(224, interpolation=transforms.InterpolationMode.BICUBIC) ,
transforms.RandomResizedCrop(224) ,
transforms.RandomHorizontalFlip(0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
# transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def transforms_train(batch):
batch["image"] = [train_transform(image.convert("RGB")) for image in batch["image"]]
return batch
def transforms_val(batch):
batch["image"] = [val_transform(image.convert("RGB")) for image in batch["image"]]
return batch
# HfFolder.save_token("your_token_here") # Save your Hugging Face token
dataset = load_dataset("imagenet-1k", cache_dir='D:\data\.cache\huggingface\datasets')
# PyTorch 데이터셋 변환
train_dataset = dataset['train'].with_format("torch")
train_dataset.set_transform(transforms_train)
val_dataset = dataset['validation'].with_format("torch")
val_dataset.set_transform(transforms_val)
def visualize_dataset(dataset, num_images=5):
for i in range(num_images):
sample = dataset[i]
image = sample['image'].permute(1, 2, 0).numpy() # Convert from CHW to HWC
image = image * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406] # Unnormalize
image = (image * 255).astype('uint8') # Denormalize and convert to uint8
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # Convert RGB to BGR for OpenCV
cv2.imshow(f"Image {i+1}", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
visualize_dataset(train_dataset)
로딩후...

결과화면 잘 출력된다.




-끝-
'Network' 카테고리의 다른 글
| [DNN] Swin Transformer 리뷰 및 구현 (ICCV 2021) (5) | 2023.04.12 |
|---|---|
| [DNN] torchvision module 이용해서 resnet-dc5 구현하기 (2) | 2023.03.21 |
| [DNN] timm을 이용한 VIT models ILSVRC classification 성능평가 (0) | 2023.03.17 |
| [DNN] multi-head cross attention vs multi-head self attention 비교 (0) | 2023.02.02 |
| performer 구현 (0) | 2022.12.12 |




댓글