안녕하세요 pulluper 입니다 😁😁
이번 포스팅에서는 pytorch 의 분산(distributed) pakage를 이용해서 multi-gpu 를 모두 효율적으로 사용하는 방법을 알아보겠습니다. 이번 포스팅의 목차는 다음과 같습니다.
1. 용어
2. init
3. dataset
4. distributed data-parallel
5. train
6. 실행
7. CIFAR 10 example
1. 용어 (terminology)
먼저 pytorch.distributed 를 이용하는 것은 멀티프로세스방법을 이용하는 것 입니다. 정확하게는 여러 process를 이용해병렬적으로 연산을 수행하여, 각 프로세스가 효율적으로 gpu를 사용하고 모으는것을 할 수 가 있습니다.

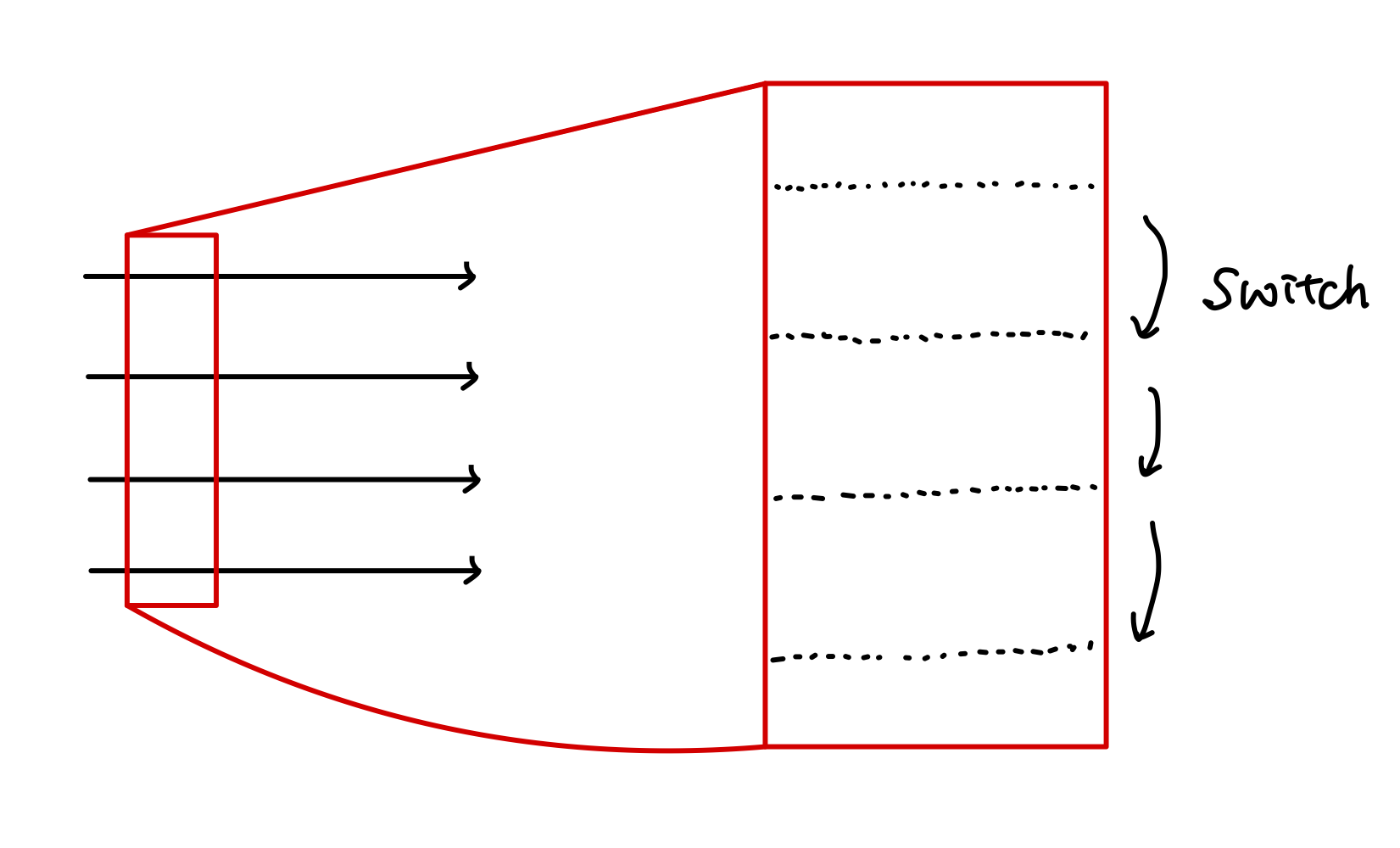
이를 이용하기 위해 이해해야 할 몇가지 용어가 있습니다.
Node : GPU가 달려있는 machine
Rank : process ID
- Local Rank : 각 node 내부의 process ID
- Global Rank : 전체 node의 입장에서의 process ID
World size : 프로세스 수
- World Size(W) : 모든 노드에서 실행되는 총 응용 프로그램 프로세스 수
- Local World Size(L) : 각 노드에서 실행되는 프로세스 수
예를들어 아래 그림에서는 node가 2이고 world size 4, local world size : 2, global rank [0, 1, 2, 3], local rank : [0, 1] 으로 볼 수 있습니다.

이 포스팅에서는 사용할수 있는 single node multi-gpus 의 예를 가지고 구현 하겠습니다.
코드는 node - 1개, wolrd - 4개, rank - [0, 1, 2, 3] 의 머신을 이용해 보겠습니다. 😎😎😎😎😎.
2. initialization
torch.distributed 를 사용하기 위해서는 초기화를 해야 합니다. 이를 위해 torch.distributed.init_process_group 이라는 함수를 이용해야 합니다. 이는 분산 패키지와 기본 분산 프로세스 그룹을 초기화 합니다.

여기서 사용되는 parameter 를 보면
backend: 백엔드설정,
init_method: peer 들을 찾기위한 분산컴퓨팅을 위한 URL 문자열
world_size: process 갯수
rank: process ID 입니다.
backend 는 우리는 GPU를 이용한 분산 학습을 하기 위함이므로, 'nccl' 을 사용하면 됩니다. (ubuntu 에서만 가능)

init_method 는하나의 node(machine) 을 사용하는 경우는 init_method 를 다음과 같이 지정합니다.
0-순위 프로세스의 IP 주소와 접근 가능한 포트 번호가 있으면 TCP를 통한 초기화를 할 수 있습니다. 모든 워커들은 0-순위의 프로세스에 연결하고 서로 정보를 교환하는 방법에 대한 정보를 공유합니다. localhost IP 인 127.0.0.1 혹은 모를때 사용하는 0.0.0.0 로 설정하면, one-node multi-gpu 에서 실행이 됩니다. port 는 '23456' 을 사용하였고, pytorch 예제에서 가져왔습니다. 더 자세한 정보는 나중에 multi-node multi-gpu 를 사용할 때 알아보겠습니다.
world_size 와 rank 는 용어 부분에서 알아보았듯이, 각각의 전체 프로세스 갯수와 현재 process ID 를 넣어줍니다.
이를 위한 intialization 예제 코드는 다음과 같습니다.
def init_for_distributed(rank, opts):
# 1. setting for distributed training
opts.rank = rank
opts.num_workers = len(opts.gpu_ids) * 4
opts.world_size = len(opts.gpu_ids)
local_gpu_id = int(opts.gpu_ids[opts.rank])
torch.cuda.set_device(local_gpu_id)
if opts.rank is not None:
print("Use GPU: {} for training".format(local_gpu_id))
# 2. init_process_group
dist.init_process_group(backend='nccl',
init_method='tcp://127.0.0.1:23456',
world_size=opts.world_size,
rank=opts.rank)
# if put this function, the all processes block at all.
torch.distributed.barrier()
# convert print fn iif rank is zero
setup_for_distributed(opts.rank == 0)
print(opts)
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
참고로 위의 코드에서 setup_for_distributed 함수는 detr 에서 가져온 것으로, master rank (rank = 0)일때만 print 하도록 설정해주는 코드입니다.
3. dataset
분산학습을 위해서는 DistributedSampler 라는 sampler 를 사용해야 합니다. 이는 pytorch 의 data loader 로 들어가는데, shuffle 을 sampler 에서 해주는 부분과, batch size, num worker 를 gpu 갯수로 나누어주는 부분을 주의하면 됩니다. 예제 코드는 다음과 같습니다.
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
train_sampler = DistributedSampler(dataset=train_set, shuffle=True)
test_sampler = DistributedSampler(dataset=test_set, shuffle=False)
train_loader = DataLoader(dataset=train_set,
batch_size=int(opts.batch_size / opts.world_size),
shuffle=False,
num_workers=int(opts.num_workers / opts.world_size),
sampler=train_sampler,
pin_memory=True)
test_loader = DataLoader(dataset=test_set,
batch_size=int(opts.batch_size / opts.world_size),
shuffle=False,
num_workers=int(opts.num_workers / opts.world_size),
sampler=test_sampler,
pin_memory=True)
batch_size 는 전체 batch_size 를 world size로 나누어 넣습니다. 이 때 batch 는 world size로 나누어 떨어야겠죠?
num_worker 는 gpu * 4 로 놓고, 로더를 작성합니다. https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813/4 (여기 참조)

참고로 리눅스에서 프로세스 갯수는 다음 명령어로 볼 수 있습니다.


제가 사용하는 서버의 경우는 36개로 num_worker 에 16개의 프로세스를 사용해도 됩니다.
4. model
이제 model 을 DistributedDataParallel 로 감쌀 차례입니다. 다음과 같이, DDP로 model 을 wrapping 해 주고, rank도 전달해 줍니다.
from torch.nn.parallel import DistributedDataParallel as DDP
model = model.cuda(opts.rank)
model = DDP(module=model,
device_ids=[opts.rank])
이렇게 rank를 넣으면, 여러 프로세스가 알아서 아래와 같은 scatter 등의 과정을 진행합니다, 우리는 단지 그냥 학습하는 것 처럼 진행해도 됩니다.

5. train
distributed training 에서 또 주의할점은 각 epoch 시작 부분에서 set_epoch() 이라는 함수를 불러야 합니다. 왜냐하면 shuffle 하는 부분을 잘 작동하게 하기 위함입니다.
train_sampler.set_epoch(epoch)
outputs = model(images)
# ----------- update -----------
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
6. 실행 (execution)
실행하는 부분은 2가지 방법을 사용 할 수 있습니다.
6 - 1. multi-processing spawn 을 이용해서 mp 이용하기
mp.spawn(main_worker,
args=(world_size, ),
nprocs=world_size,
join=True)
def main_worker(gpu, ngpus_per_node, args):
# main ~
6 - 2. python -m torch.distributed.launch 이용하기
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=2 --node_rank=0 --master_addr="127.0.0.1" --master_port=23456 main.py
이를 이용하면, multi-node 학습등에 더 유용하므로, 이를 추천드립니다.
** 2022.10.31 추가 ** (수행)
python -m torch.distributed.launch --nproc_per_node=4 main.py
import os
import time
import torch
import visdom
import argparse
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.optim.lr_scheduler import StepLR
# for dataset
from torchvision.datasets.cifar import CIFAR10
import torchvision.transforms as tfs
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
# for model
from torchvision.models import vgg11
from torch.nn.parallel import DistributedDataParallel as DDP
def get_args_parser():
parser = argparse.ArgumentParser(add_help=False)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--epoch', type=int, default=90)
parser.add_argument('--batch_size', type=int, default=256)
parser.add_argument('--rank', type=int, default=0)
parser.add_argument('--vis_step', type=int, default=10)
parser.add_argument('--num_workers', type=int, default=16)
# parser.add_argument('--gpu_ids', nargs="+", default=['0'])
# parser.add_argument('--gpu_ids', nargs="+", default=['0', '1'])
# parser.add_argument('--gpu_ids', nargs="+", default=['0', '1', '2'])
parser.add_argument('--gpu_ids', nargs="+", default=['0', '1', '2', '3'])
parser.add_argument('--world_size', type=int, default=0)
parser.add_argument('--port', type=int, default=2022)
parser.add_argument('--root', type=str, default='./cifar')
parser.add_argument('--start_epoch', type=int, default=0)
parser.add_argument('--save_path', type=str, default='./save')
parser.add_argument('--save_file_name', type=str, default='vgg_cifar')
parser.add_argument('--local_rank', type=int)
parser.add_argument('--dist_url', type=str)
# usage : --gpu_ids 0, 1, 2, 3
return parser
def main(opts):
# 1. argparse (main)
# 2. init dist
init_for_distributed(opts)
local_gpu_id = opts.gpu
# 3. visdom
vis = visdom.Visdom(port=opts.port)
# 4. data set
transform_train = tfs.Compose([
tfs.Resize(256),
tfs.RandomCrop(224),
tfs.RandomHorizontalFlip(),
tfs.ToTensor(),
tfs.Normalize(mean=(0.4914, 0.4822, 0.4465),
std=(0.2023, 0.1994, 0.2010)),
])
transform_test = tfs.Compose([
tfs.Resize(256),
tfs.CenterCrop(224),
tfs.ToTensor(),
tfs.Normalize(mean=(0.4914, 0.4822, 0.4465),
std=(0.2023, 0.1994, 0.2010)),
])
train_set = CIFAR10(root=opts.root,
train=True,
transform=transform_train,
download=True)
test_set = CIFAR10(root=opts.root,
train=False,
transform=transform_test,
download=True)
train_sampler = DistributedSampler(dataset=train_set, shuffle=True)
test_sampler = DistributedSampler(dataset=test_set, shuffle=False)
# train_loader = DataLoader(dataset=train_set,
# batch_size=int(opts.batch_size / opts.world_size),
# shuffle=False,
# num_workers=int(opts.num_workers / opts.world_size),
# sampler=train_sampler,
# pin_memory=True)
# 2
sampler_train = DistributedSampler(train_set, shuffle=False)
batch_sampler_train = torch.utils.data.BatchSampler(sampler_train, opts.batch_size, drop_last=True)
train_loader = DataLoader(train_set, batch_sampler=batch_sampler_train, num_workers=opts.num_workers)
test_loader = DataLoader(dataset=test_set,
batch_size=int(opts.batch_size / opts.world_size),
shuffle=False,
num_workers=int(opts.num_workers / opts.world_size),
sampler=test_sampler,
pin_memory=True)
# 5. model
model = vgg11(pretrained=False)
model = model.cuda(local_gpu_id)
model = DDP(module=model,
device_ids=[local_gpu_id])
# 6. criterion
criterion = torch.nn.CrossEntropyLoss().to(local_gpu_id)
# 7. optimizer
optimizer = torch.optim.SGD(params=model.parameters(),
lr=0.01,
weight_decay=0.0005,
momentum=0.9)
# 8. scheduler
scheduler = StepLR(optimizer=optimizer,
step_size=30,
gamma=0.1)
if opts.start_epoch != 0:
checkpoint = torch.load(os.path.join(opts.save_path, opts.save_file_name) + '.{}.pth.tar'
.format(opts.start_epoch - 1),
map_location=torch.device('cuda:{}'.format(local_gpu_id)))
model.load_state_dict(checkpoint['model_state_dict']) # load model state dict
optimizer.load_state_dict(checkpoint['optimizer_state_dict']) # load optim state dict
scheduler.load_state_dict(checkpoint['scheduler_state_dict']) # load sched state dict
if opts.rank == 0:
print('\nLoaded checkpoint from epoch %d.\n' % (int(opts.start_epoch) - 1))
for epoch in range(opts.start_epoch, opts.epoch):
# 9. train
tic = time.time()
model.train()
train_sampler.set_epoch(epoch)
for i, (images, labels) in enumerate(train_loader):
images = images.to(local_gpu_id)
labels = labels.to(local_gpu_id)
outputs = model(images)
# ----------- update -----------
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# get lr
for param_group in optimizer.param_groups:
lr = param_group['lr']
# time
toc = time.time()
# visualization
if (i % opts.vis_step == 0 or i == len(train_loader) - 1) and opts.rank == 0:
print('Epoch [{0}/{1}], Iter [{2}/{3}], Loss: {4:.4f}, LR: {5:.5f}, Time: {6:.2f}'.format(epoch,
opts.epoch, i,
len(train_loader),
loss.item(),
lr,
toc - tic))
vis.line(X=torch.ones((1, 1)) * i + epoch * len(train_loader),
Y=torch.Tensor([loss]).unsqueeze(0),
update='append',
win='loss',
opts=dict(x_label='step',
y_label='loss',
title='loss',
legend=['total_loss']))
# save pth file
if opts.rank == 0:
if not os.path.exists(opts.save_path):
os.mkdir(opts.save_path)
checkpoint = {'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict()}
torch.save(checkpoint, os.path.join(opts.save_path, opts.save_file_name + '.{}.pth.tar'.format(epoch)))
print("save pth.tar {} epoch!".format(epoch))
# 10. test
if opts.rank == 0:
model.eval()
val_avg_loss = 0
correct_top1 = 0
correct_top5 = 0
total = 0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images = images.to(opts.rank) # [100, 3, 224, 224]
print("batch_size : ", images.size(0))
labels = labels.to(opts.rank) # [100]
outputs = model(images)
loss = criterion(outputs, labels)
val_avg_loss += loss.item()
# ------------------------------------------------------------------------------
# rank 1
_, pred = torch.max(outputs, 1)
total += labels.size(0)
correct_top1 += (pred == labels).sum().item()
# ------------------------------------------------------------------------------
# rank 5
_, rank5 = outputs.topk(5, 1, True, True)
rank5 = rank5.t()
correct5 = rank5.eq(labels.view(1, -1).expand_as(rank5))
# ------------------------------------------------------------------------------
for k in range(5): # 0, 1, 2, 3, 4, 5
correct_k = correct5[:k+1].reshape(-1).float().sum(0, keepdim=True)
correct_top5 += correct_k.item()
accuracy_top1 = correct_top1 / total
accuracy_top5 = correct_top5 / total
val_avg_loss = val_avg_loss / len(test_loader) # make mean loss
if vis is not None:
vis.line(X=torch.ones((1, 3)) * epoch,
Y=torch.Tensor([accuracy_top1, accuracy_top5, val_avg_loss]).unsqueeze(0),
update='append',
win='test_loss_acc',
opts=dict(x_label='epoch',
y_label='test_loss and acc',
title='test_loss and accuracy',
legend=['accuracy_top1', 'accuracy_top5', 'avg_loss']))
print("top-1 percentage : {0:0.3f}%".format(correct_top1 / total * 100))
print("top-5 percentage : {0:0.3f}%".format(correct_top5 / total * 100))
scheduler.step()
return 0
def init_for_distributed(opts):
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
opts.rank = int(os.environ["RANK"])
opts.world_size = int(os.environ['WORLD_SIZE'])
opts.gpu = int(os.environ['LOCAL_RANK'])
elif 'SLURM_PROCID' in os.environ:
opts.rank = int(os.environ['SLURM_PROCID'])
opts.gpu = opts.rank % torch.cuda.device_count()
else:
print('Not using distributed mode')
opts.distributed = False
return
# 1. setting for distributed training
# opts.rank = rank
# local_gpu_id = int(opts.gpu_ids[opts.rank])
# torch.cuda.set_device(local_gpu_id)
# if opts.rank is not None:
# print("Use GPU: {} for training".format(local_gpu_id))
torch.cuda.set_device(opts.gpu)
opts.dist_backend = 'nccl'
print('| distributed init (rank {}): {}'.format(
opts.rank, 'env://'), flush=True)
torch.distributed.init_process_group(backend=opts.dist_backend, init_method=opts.dist_url,
world_size=opts.world_size, rank=opts.rank)
torch.distributed.barrier()
setup_for_distributed(opts.rank == 0)
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
if __name__ == '__main__':
parser = argparse.ArgumentParser('vgg11 cifar training', parents=[get_args_parser()])
opts = parser.parse_args()
opts.world_size = len(opts.gpu_ids)
opts.num_workers = len(opts.gpu_ids) * 4
main(opts)
7. example (CIFAR10)
마지막으로 cifar10 에 대한 여러 gpu 사용하기 예제를 보여드리겠습니다. (nnode = 1, nproc_per_node=4 (world size))
import os
import time
import torch
import visdom
import argparse
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.optim.lr_scheduler import StepLR
# for dataset
from torchvision.datasets.cifar import CIFAR10
import torchvision.transforms as tfs
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
# for model
from torchvision.models import vgg11
from torch.nn.parallel import DistributedDataParallel as DDP
def get_args_parser():
parser = argparse.ArgumentParser(add_help=False)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--epoch', type=int, default=90)
parser.add_argument('--batch_size', type=int, default=1024)
parser.add_argument('--rank', type=int, default=0)
parser.add_argument('--vis_step', type=int, default=10)
parser.add_argument('--num_workers', type=int, default=16)
# parser.add_argument('--gpu_ids', nargs="+", default=['0'])
# parser.add_argument('--gpu_ids', nargs="+", default=['0', '1'])
# parser.add_argument('--gpu_ids', nargs="+", default=['0', '1', '2'])
parser.add_argument('--gpu_ids', nargs="+", default=['0', '1', '2', '3'])
parser.add_argument('--world_size', type=int, default=0)
parser.add_argument('--port', type=int, default=2022)
parser.add_argument('--root', type=str, default='./cifar')
parser.add_argument('--start_epoch', type=int, default=0)
parser.add_argument('--save_path', type=str, default='./save')
parser.add_argument('--save_file_name', type=str, default='vgg_cifar')
# usage : --gpu_ids 0, 1, 2, 3
return parser
def main_worker(rank, opts):
# 1. argparse (main)
# 2. init dist
local_gpu_id = init_for_distributed(rank, opts)
# 3. visdom
vis = visdom.Visdom(port=opts.port)
# 4. data set
transform_train = tfs.Compose([
tfs.Resize(256),
tfs.RandomCrop(224),
tfs.RandomHorizontalFlip(),
tfs.ToTensor(),
tfs.Normalize(mean=(0.4914, 0.4822, 0.4465),
std=(0.2023, 0.1994, 0.2010)),
])
transform_test = tfs.Compose([
tfs.Resize(256),
tfs.CenterCrop(224),
tfs.ToTensor(),
tfs.Normalize(mean=(0.4914, 0.4822, 0.4465),
std=(0.2023, 0.1994, 0.2010)),
])
train_set = CIFAR10(root=opts.root,
train=True,
transform=transform_train,
download=True)
test_set = CIFAR10(root=opts.root,
train=False,
transform=transform_test,
download=True)
train_sampler = DistributedSampler(dataset=train_set, shuffle=True)
test_sampler = DistributedSampler(dataset=test_set, shuffle=False)
train_loader = DataLoader(dataset=train_set,
batch_size=int(opts.batch_size / opts.world_size),
shuffle=False,
num_workers=int(opts.num_workers / opts.world_size),
sampler=train_sampler,
pin_memory=True)
test_loader = DataLoader(dataset=test_set,
batch_size=int(opts.batch_size / opts.world_size),
shuffle=False,
num_workers=int(opts.num_workers / opts.world_size),
sampler=test_sampler,
pin_memory=True)
# 5. model
model = vgg11(pretrained=False)
model = model.cuda(local_gpu_id)
model = DDP(module=model,
device_ids=[local_gpu_id])
# 6. criterion
criterion = torch.nn.CrossEntropyLoss().to(local_gpu_id)
# 7. optimizer
optimizer = torch.optim.SGD(params=model.parameters(),
lr=0.01,
weight_decay=0.0005,
momentum=0.9)
# 8. scheduler
scheduler = StepLR(optimizer=optimizer,
step_size=30,
gamma=0.1)
if opts.start_epoch != 0:
checkpoint = torch.load(os.path.join(opts.save_path, opts.save_file_name) + '.{}.pth.tar'
.format(opts.start_epoch - 1),
map_location=torch.device('cuda:{}'.format(local_gpu_id)))
model.load_state_dict(checkpoint['model_state_dict']) # load model state dict
optimizer.load_state_dict(checkpoint['optimizer_state_dict']) # load optim state dict
scheduler.load_state_dict(checkpoint['scheduler_state_dict']) # load sched state dict
if opts.rank == 0:
print('\nLoaded checkpoint from epoch %d.\n' % (int(opts.start_epoch) - 1))
for epoch in range(opts.start_epoch, opts.epoch):
# 9. train
tic = time.time()
model.train()
train_sampler.set_epoch(epoch)
for i, (images, labels) in enumerate(train_loader):
images = images.to(local_gpu_id)
labels = labels.to(local_gpu_id)
outputs = model(images)
# ----------- update -----------
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# get lr
for param_group in optimizer.param_groups:
lr = param_group['lr']
# time
toc = time.time()
# visualization
if (i % opts.vis_step == 0 or i == len(train_loader) - 1) and opts.rank == 0:
print('Epoch [{0}/{1}], Iter [{2}/{3}], Loss: {4:.4f}, LR: {5:.5f}, Time: {6:.2f}'.format(epoch,
opts.epoch, i,
len(train_loader),
loss.item(),
lr,
toc - tic))
vis.line(X=torch.ones((1, 1)) * i + epoch * len(train_loader),
Y=torch.Tensor([loss]).unsqueeze(0),
update='append',
win='loss',
opts=dict(x_label='step',
y_label='loss',
title='loss',
legend=['total_loss']))
# save pth file
if opts.rank == 0:
if not os.path.exists(opts.save_path):
os.mkdir(opts.save_path)
checkpoint = {'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict()}
torch.save(checkpoint, os.path.join(opts.save_path, opts.save_file_name + '.{}.pth.tar'.format(epoch)))
print("save pth.tar {} epoch!".format(epoch))
# 10. test
if opts.rank == 0:
model.eval()
val_avg_loss = 0
correct_top1 = 0
correct_top5 = 0
total = 0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images = images.to(opts.rank) # [100, 3, 224, 224]
labels = labels.to(opts.rank) # [100]
outputs = model(images)
loss = criterion(outputs, labels)
val_avg_loss += loss.item()
# ------------------------------------------------------------------------------
# rank 1
_, pred = torch.max(outputs, 1)
total += labels.size(0)
correct_top1 += (pred == labels).sum().item()
# ------------------------------------------------------------------------------
# rank 5
_, rank5 = outputs.topk(5, 1, True, True)
rank5 = rank5.t()
correct5 = rank5.eq(labels.view(1, -1).expand_as(rank5))
# ------------------------------------------------------------------------------
for k in range(5): # 0, 1, 2, 3, 4, 5
correct_k = correct5[:k+1].reshape(-1).float().sum(0, keepdim=True)
correct_top5 += correct_k.item()
accuracy_top1 = correct_top1 / total
accuracy_top5 = correct_top5 / total
val_avg_loss = val_avg_loss / len(test_loader) # make mean loss
if vis is not None:
vis.line(X=torch.ones((1, 3)) * epoch,
Y=torch.Tensor([accuracy_top1, accuracy_top5, val_avg_loss]).unsqueeze(0),
update='append',
win='test_loss_acc',
opts=dict(x_label='epoch',
y_label='test_loss and acc',
title='test_loss and accuracy',
legend=['accuracy_top1', 'accuracy_top5', 'avg_loss']))
print("top-1 percentage : {0:0.3f}%".format(correct_top1 / total * 100))
print("top-5 percentage : {0:0.3f}%".format(correct_top5 / total * 100))
scheduler.step()
return 0
def init_for_distributed(rank, opts):
# 1. setting for distributed training
opts.rank = rank
local_gpu_id = int(opts.gpu_ids[opts.rank])
torch.cuda.set_device(local_gpu_id)
if opts.rank is not None:
print("Use GPU: {} for training".format(local_gpu_id))
# 2. init_process_group
dist.init_process_group(backend='nccl',
init_method='tcp://127.0.0.1:23456',
world_size=opts.world_size,
rank=opts.rank)
# if put this function, the all processes block at all.
torch.distributed.barrier()
# convert print fn iif rank is zero
setup_for_distributed(opts.rank == 0)
print(opts)
return local_gpu_id
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
if __name__ == '__main__':
parser = argparse.ArgumentParser('vgg11 cifar training', parents=[get_args_parser()])
opts = parser.parse_args()
opts.world_size = len(opts.gpu_ids)
opts.num_workers = len(opts.gpu_ids) * 4
# main_worker(opts.rank, opts)
mp.spawn(main_worker,
args=(opts, ),
nprocs=opts.world_size,
join=True)
일부로 하나의 gpu 에서 돌릴수 없는 224 x 224 size의 cifar dataset을 batch size 1024에 대해서 돌린 결과
gpu 1, 2 개에서는 CUDA out of memory 에러가 났고,
RuntimeError: CUDA out of memory. Tried to allocate 784.00 MiB (GPU 0; 23.70 GiB total capacity; 20.80 GiB already allocated; 394.81 MiB free; 21.33 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
3개는 1 epoch 에 45초가 걸렸고
Epoch [0/90], Iter [0/49], Loss: 6.9032, LR: 0.01000, Time: 10.95
Epoch [0/90], Iter [10/49], Loss: 6.7351, LR: 0.01000, Time: 17.65
Epoch [0/90], Iter [20/49], Loss: 6.7121, LR: 0.01000, Time: 24.82
Epoch [0/90], Iter [30/49], Loss: 6.0347, LR: 0.01000, Time: 32.00
Epoch [0/90], Iter [40/49], Loss: 5.0564, LR: 0.01000, Time: 39.19
Epoch [0/90], Iter [48/49], Loss: 3.2871, LR: 0.01000, Time: 45.02
4개는 1 epoch 에 32초 정도가 걸렸습니다.
Epoch [0/90], Iter [0/49], Loss: 6.9055, LR: 0.01000, Time: 9.87
Epoch [0/90], Iter [10/49], Loss: 6.6714, LR: 0.01000, Time: 14.45
Epoch [0/90], Iter [20/49], Loss: 6.0993, LR: 0.01000, Time: 19.25
Epoch [0/90], Iter [30/49], Loss: 3.8385, LR: 0.01000, Time: 24.06
Epoch [0/90], Iter [40/49], Loss: 3.1381, LR: 0.01000, Time: 28.87
Epoch [0/90], Iter [48/49], Loss: 2.4679, LR: 0.01000, Time: 32.62
물론 gpu uitls 는 100% 에 가깝습니다 :)

이번 포스팅에서는 pytorch 의 분산(distributed) pakage를 이용해서 multi-gpu 를 모두 효율적으로 사용하는 방법을 알아보았습니다. 다음에는 multi-node multi-gpu 의 학습에 대하여 알아보겠습니다.
질문과 의견은 항상 환영합니다. 감사합니다. 😎😎😎😎👍
** 2023.04.26 추가 **
위의 방법은 multi-gpu를 사용하는데 좋습니다.
그러나 더 대규모의 학습을 진행하기 위해서는
multi-node + multi-gpu 의 학습방법을 알아야 합니다.
이에 새로운 포스팅에서 그 방법을 설명합니다.
아래를 참조해 주세요.
감사합니다.
↓↓↓↓↓↓
[pytorch] Distributed package으로 Multi-Node Multi-GPU 학습 알아보기
안녕하세요 pulluper입니다! 이번 포스팅에서는 저번 포스팅에 이어서 pytorch 의 분산(distributed) pakage를 이용한 mutli-node의 multi-gpu 환경에서 학습을 하는 방법을 알아보겠습니다. 기본적인 용어등의
csm-kr.tistory.com
**********************************************************
2023.04.26 torch.distributed 를 통한 multi-node 포스팅 완료
**********************************************************
reference :
https://pytorch.org/docs/stable/distributed.html
https://github.com/pytorch/examples/blob/main/distributed/ddp/README.md
'Pytorch' 카테고리의 다른 글
| [Pytorch] 분류(classification)문제 에서 label 변환 (one-hot vs class) (0) | 2022.12.04 |
|---|---|
| [Pytorch] pytorch 에서 np.where 처럼 index 가져오기 (0) | 2022.08.17 |
| [Pytorch] PIL, cv2, pytorch 이미지 처리 library 비교 (2) | 2022.04.11 |
| [Python] python model config 하기 - configuration (argparse, ymal) 이용 (0) | 2021.09.14 |
| [Pytorch] window cuda v9.0, pytorch1.2.0 에서 cuda v10.1, pytorch 1.5.0 설치하기 (6) | 2020.06.17 |



댓글