안녕하세요~ pulluper 입니다. 오늘은 deep neural network 를 학습할 때, 그 구성을 변경하는데 많이 쓰이는 argparse 와 ymal 에 대하여 알아보겠습니다. 😊
대규모 혹은 논문을 위한 실험은 여러가지의 구성요소를 고려해야 합니다. 어떤 model 을 학습할 때, 최적의 hyper-parameter 를 찾기 위해서 learning rate, epoch등을 바꾸면서 실험을 해야 합니다.
예를들어 Learning rate 에 따른 performance 의 변화를 알고 싶다고 합시다. 이때, 매번 실험 할 때마다 코드상에서 learning rate 를 바꾸어 주는것 보다 프로그램 외부에서 입력을 하여 그 요소만 변하게 하는 것이 효율적입니다.
또한 github등에서 프로젝트를 다운받아 실험 할 때, 컴퓨터마다 환경과 경로등이 다르기 때문에 data의 path 를 변경하는 등의 작업이 필요합니다.
이를 위해서 많이 사용되는 방법은 argparse 혹은 yaml 을 이용하는 방법입니다.

1. argparse 이용방법
첫 번째는 argparse 를 이용하는 방법입니다.
예를들어 argparse_ex.py 라는 python 파일을 만들어 보겠습니다.
여기에서 다음과같이 parser 를 만들고 add_argument 로 여러가지 필요한 요소들을 추가 해 줄 수 있습니다.
'--epoch' 이라는 인자의 type 은 int 이고, default 값은 10 으로 정해주었습니다.
더 자세하고 다양한 문법들은 구글링을 추천드립니다. ㅎㅎ
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--epoch', type=int, default=10)
parser.add_argument('--data_root', type=str, default='D:\data\coco')
parser.add_argument('--lr', type=float, default=1e-2)
parser.add_argument('--batch_size', type=int, default=256)
parser.add_argument('--momentum', type=float, default=0.9)
parser.add_argument('--weight_decay', type=float, default=5e-4)
opts = parser.parse_args()
print(opts)
batch_size = opts.batch_size
print(batch_size)이때, CLI 에서 python argparse_ex.py 를 입력하면 defalut 값들로 초기화된 요소들을 볼 수 있습니다.
~>python argparse_ex.py
Namespace(batch_size=256, data_root='D:\\data\\coco', epoch=10, lr=0.01, momentum=0.9, weight_decay=0.0005)
10그리고 parser를 통한 값에 접근을 위해서는 opts.~("요소이름") 로 접근을 할 수 있습니다.
여기서 우리가 만약 epoch 을 20 으로 ,lr 을 1e-3 으로 바꾸고 싶을 때 CLI 에서 다음과 같이 뒤에 인자를 넣어줍니다.
~>python argparse_ex.py --epoch 20 --lr 1e-3
Namespace(batch_size=256, data_root='D:\\data\\coco', epoch=20, lr=0.001, momentum=0.9, weight_decay=0.0005)
20이런 argparse 를 이용한 configuration 변경에는 간단한 변환 작업을 할 때, 유용합니다.
그런데, 더 대규모의 예정된 실험이라면, 모든 인자들을 한번에 cover하는것이 다소 불편할 때가 있습니다.
이때 .ymal 파일은 이용한 config 가 더 유용합니다.
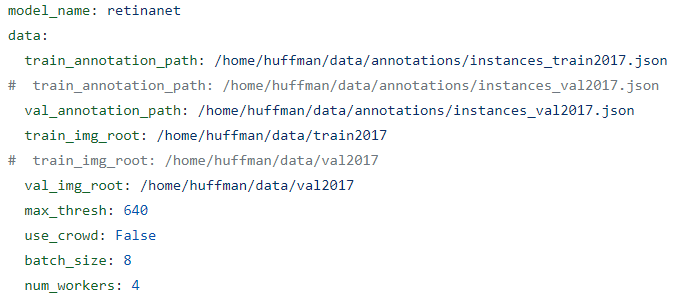
2. yaml 파일 이용하기
이번에는 .yaml 파일을 이용한 방법입니다.
YAML 파일은 Yet Another Markup Language 의 약자로,
xml 이나 json 과 같이 데이터에 관한 포맷이 정해져 있는 파일입니다.
특히 yaml 은 가독성이 좋기로 유명합니다. 😁

예를들어 다음과 같은 config.yaml 이라는 파일을 만들어 줍니다.
epoch: 10
data_root: 'D:\data\coco'
lr: 1e-2
batch_size: 256
momentum: 0.9
weight_decay: 5e-4그리고 이번에는 yaml_ex.py 라는 파일을 만들어 보겠습니다.
import yaml
if __name__ == '__main__':
with open('./config.yaml') as f:
config = yaml.safe_load(f)
print(config)
epoch = config['epoch']
print(epoch)이를 실행시키면 yaml.safe_load() 로 읽은 data 는 dict 로 만들어지게 됩니다.
이를 접근 할때는 dict['key'] 처럼 쉽게 접근 가능합니다.
{'epoch': 10, 'data_root': 'D:\\data\\coco', 'lr': '1e-2', 'batch_size': 256, 'momentum': 0.9, 'weight_decay': '5e-4'}
10
필요에 따라 좀더 계층적으로 설정도 가능합니다. (argparse 도 계층적으로 이용가능합니다 ^^)
training_parameter:
decay_step :
- 30
- 60
- 90
epoch: 10
data_root: 'D:\data\coco'
lr: 1e-2
batch_size: 256
momentum: 0.9
weight_decay: 5e-4yaml 도 더 자세하고 다양한 문법들은 구글링을 추천드립니다. 😀
이를통해 좀더 편리한 model 에 대한 config 를 다룰 수 있도록 되었습니다.
필요에따라 argparse 나 yaml 을 이용하여 편리하게 변경을 하면서 실험 하시길 바랍니다.
감사합니다. 😎
사용된 코드는 다음과 같습니다.
https://github.com/csm-kr/python_argparse_yaml
Reference
https://github.com/csm-kr/Retinanet_pytorch/blob/master/config.py
GitHub - csm-kr/Retinanet_pytorch
Contribute to csm-kr/Retinanet_pytorch development by creating an account on GitHub.
github.com
https://github.com/liangheming/retinanetv1/blob/snap_shot/config/retina.yaml
GitHub - liangheming/retinanetv1: pytorch implement of retinanet,37.4 mAp(coco) at 640px(max side) ,44.24fps(RTX2080TI)
pytorch implement of retinanet,37.4 mAp(coco) at 640px(max side) ,44.24fps(RTX2080TI) - GitHub - liangheming/retinanetv1: pytorch implement of retinanet,37.4 mAp(coco) at 640px(max side) ,44.24fps(...
github.com
https://www.inflearn.com/questions/16184
yaml파일 이란 무엇인가요 - 인프런 | 질문 & 답변
안녕하세요 강사님 너무 질문이 많아서 죄송합니다. yaml파일 이라는 단어를 요 근래 많이 듣고 있는데 정확인 무슨 파일인가요 검색해 보지도 않고 무조건 질문을 드리는것 같아서 죄송하지만
www.inflearn.com
'Pytorch' 카테고리의 다른 글
| [Pytorch] 분류(classification)문제 에서 label 변환 (one-hot vs class) (0) | 2022.12.04 |
|---|---|
| [Pytorch] pytorch 에서 np.where 처럼 index 가져오기 (0) | 2022.08.17 |
| [Pytorch] Distributed package 를 이용한 분산학습으로 Multi-GPU 효율적으로 사용하기 (8) | 2022.06.15 |
| [Pytorch] PIL, cv2, pytorch 이미지 처리 library 비교 (2) | 2022.04.11 |
| [Pytorch] window cuda v9.0, pytorch1.2.0 에서 cuda v10.1, pytorch 1.5.0 설치하기 (6) | 2020.06.17 |



댓글