
안녕하세요 pulluper 입니다 :)
이번에는 one-stage detection의 시초라고 할수 있는 yolo 의 version 2 에 대하여 알아보겠습니다.
yolo 라는 이름은 (you only look once) 의 줄임말인데요, 이 시기에는 Faster rcnn toward real-time ~ 이라는
2 stage detection 이 나온 상태며, 속도는 5 fps 정도로 논문에 나와있었습니다. 이것이 빠른 축에 속해있기 때문에
yolo 는 비슷한 성능을 내면서도 속도가 매우 빠르다는 것을 장점으로 내세워 이런 이름을 정하였습니다.
2020 년 7월 기준으로 yolo v5 라는 이름의 github repo version 까지 나와있습니다.
https://github.com/ultralytics/yolov5
ultralytics/yolov5
YOLOv5 in PyTorch > ONNX > CoreML > iOS. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
github.com
그러나 저자의 홈페이지에서는 https://pjreddie.com/darknet/yolo/yolo v3까지만 소개하고 있어서 v4, v5는 다른 분들의
작품임을 알 수 있습니다.
YOLO: Real-Time Object Detection
YOLO: Real-Time Object Detection You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev. Comparison to Other Detectors YOLOv3 is extremel
pjreddie.com
YOLO v2 를 다음과 같은 관점들로 알아보겠습니다.
1. Introduction
2. Dataset
3. Model
4. Loss
5. Train
6. Evaluation & Results
1. Introduction
YOLO v2 는 빠릅니다. 왜 빠를까요?
이전의 2 stage detection 들이 region proposal 을 하고 bbox regression 과 classification 을 진행을 했다면 이 2가지를
한번에 진행하였기 때문입니다. 또한 network를 경량화 시킨것도 빠른 이유중에 하나입니다.
여기서 YOLO v2 의 핵심은 grid cell 과 anchor를 이용한 것이라고 말하고 싶습니다.
yolo v2 의 마지막 layer 에서 $416 \times 416$ resolution 의 이미지는 $13\times13$ 의 (grid-cell)
features 로 mapping 됩니다.

각 grid cell은 5개의 anchor box에 대한 정보를 포함합니다.
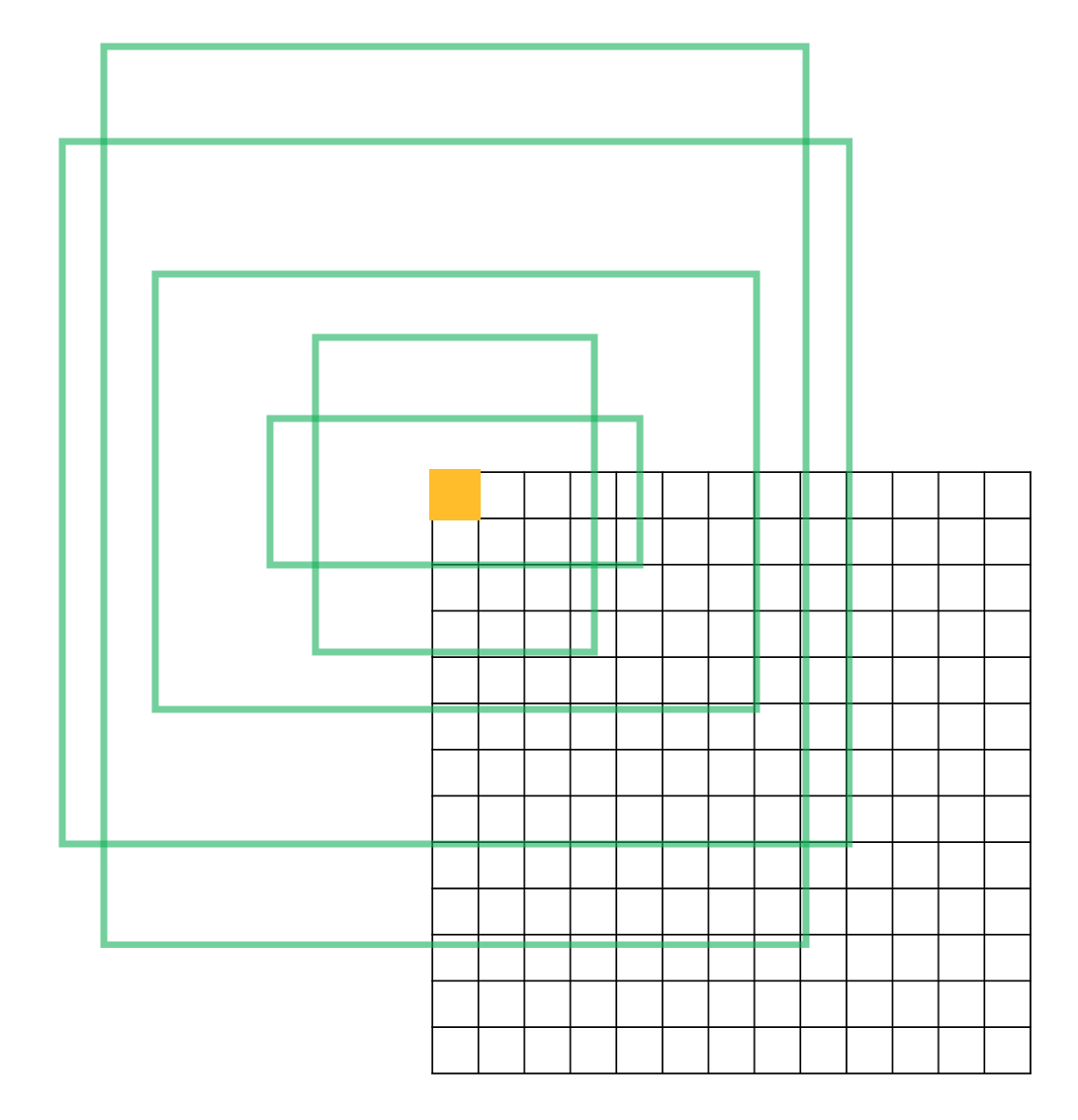
grid cell 의 갯수는 13 $\times$ 13 이고, 각 grid cell 은 5 개의 anchor 를 지니므로, 총 anchor 의 갯수는 13 $\times$
13 $\times$ 5개 입니다.
Faster rcnn 과 비교해보면, rpn 에서 제안된 proposition과 같은 역할을 yolo v2 에서는 845개의 anchor 들이 담당하며,
각 anchor 에 대해서 bbox 의 위치와 class 를 예측합니다.
2. Dataset
object detection 들이 기본적으로 사용하는 VOC dataset 과 MS COCO dataset benchmark 를 이용하였습니다.
Data Augmentation 논문에서는 YOLO 나 SSD 와 같이 random crops, color shifting, 등을 사용했다고 나와있습니다.
3. Model
darknet 19
darknet 19는 yolo v2 를 위한 새로운 classification network 입니다.
NIN(network in network) 방식을 사용하여 VGG 계열들과는 다르게 3 $\times$ 3 conv 사이에
feature 압축을 위한 1 $\times$ 1 conv 를 사용하였습니다.
그리고 training 을 통해서 vgg 16 대비 약 30% 적은 parmeter 를 가지고, 더 정확한 accuracy 를 가지는
yolo v2 의 baseline 이 되는 classification network 를 제안하였습니다.
darknet 19 의 network 는 다음과 같습니다.

Yolo v2 network
yolo v2의 network 는 다음과 같습니다.
기본적으로 darknet 19 의 feature extraction 부분을 사용하였고,
특이한점은 darknet 의 중간의 feature 를 뽑아서 reorganization 을 통해 나온 feature 를
final feature 이전에 concatenation 을 통해 네트워크의 상대적으로 얕은 feature 의 특징들을
(논문에서는 작은 object 를 detection 하는데 이점을 주는 feature라고 주장합니다.)
전달해 주는 passthrough layer 사용한 것입니다.
저자는 이를 Fine-Grained Features 라 하였습니다.

network 의 output 을 보시면,
[B, 13, 13, 125] (B - batch_size) 의 size 를 가짐을 알 수 있습니다.
여기서 앞에 13, 13 은 최종 grid cell 의 width 와 height 를 나타냅니다.
이후 125 가 뜻하는것은 5개의 anchor 에 대하여, prediction 을 하는데 각 prediction 은
x, y, w, h, c, class0, class1, class2, ... class19 를 의미하기 때문에 5 x (5 + 20) 의 output
을 가짐을 알 수 있습니다. class 의 경우 voc 의 class 가 20개 이기 때문에 이와같이 표현했습니다.
실제 network 의 output 과 bounding box 그리고, class label 의 loss 에서의 과정은 아래에서 설명합니다 :)
4. Loss
yolo 의 loss 를 보면 다음과 같습니다.
처음 yolo v1 에서 소개한 loss 를 version 이 upgrade 됨에도 조금씩 변형하여 계속 사용하므로,
이해를 잘 해놓으시면 다른 version 의 yolo 나 one-stage detection 들의 loss 를 이해하는데 도움이 될 것입니다.
차근차근 용어들을 먼저 파악하고 따라가신다면 쉽게 이해가 가능합니다.
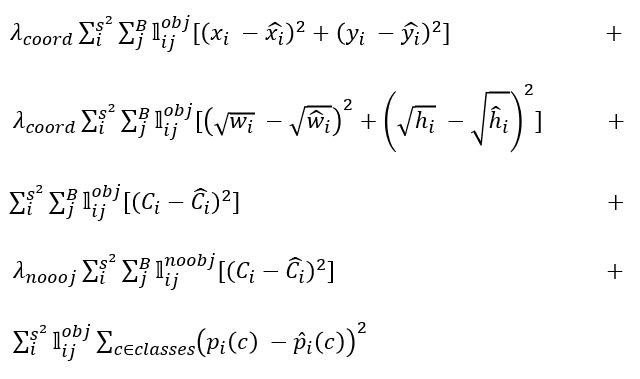
먼저 terminology 부터 알아보겠습니다.
$\lambda_{coord}$ : coordinate loss 에 들어가는 balance 를 맞춰주는 상수로써 5 입니다.
$\lambda_{noobj}$ : no confidence loss 에 들어가는 상수로 0.5 입니다.
$𝕝_{𝑖}^{𝑜𝑏𝑗}$ : object 가 cell i 안에 존재하는가의 여부입니다. 즉, gt_bbox 의 중심점이 어떤 cell 안에 들어있다면 이는
1이고 그렇지 않다면, 0 입니다. (13, 13) 의 size 를 가집니다.
$𝕝_{𝑖𝑗}^{𝑜𝑏𝑗}$ : "responsible" 로 불려지며, cell 안에는 3개의 predictor(anchor) 이 존재합니다. 이때 어떤 predictor가
gt와 최대의 iou 를 갖는가를 알려주는 기호입니다.
size 는 (13, 13, 5) 이고 각 cell 안의 최대의 iou 를 갖는 predictor(anchor) 의 값은 1, 그렇지 않으면 0입니다.
$𝕝_{𝑖𝑗}^{no𝑜𝑏𝑗}$ : "not responsible" 의 개념이며, size 는 (13, 13, 5) 이고 ~$𝕝_{𝑖𝑗}^{𝑜𝑏𝑗}$ 입니다.

$x_{i}, y_{i}, w_{i}, h_{i}$ : gt bounding box 가아니라, anchor 와의 연산을 통해 만들어진 값 입니다.
"responsible" 한 prediction 에 대해서, 그때의 anchor box(prior box) 를
$p_{x}, p_{y}, p_{w}, p_{h}$ = [12.5, 9.5, 3.19, 4.00] 라고 가정해 봅시다. ((x_c, y_c, w, h) 의 coord 에서)
또한 $c_{x}, c_{y}$ 는 cell 의 왼쪽 상단의 값을 뜻하므로 다음과 같이 표현 할 수 있습니다.
$c_{x}$ = $\lfloor p_{x} \rfloor$, $c_{y}$ = $\lfloor p_{y} \rfloor$.
그리고 그 때의 gt bounding box 를 $b_{x}, b_{y}, b_{w}, b_{h}$ = [12.76, 9.9, 3.7, 4.5] 라고 한다면,
$x_{i}$ = $b_{x}$ - $c_{x}$ = 0.76
$y_{i}$ = $b_{y}$ - $c_{y}$ = 0.9
$w_{i}$ = $b_{x}$ / $p_{w}$ = 3.7 / 3.19
$h_{i}$ = $b_{y}$ / $h_{y}$ = 4.5 / 4.00
$\hat{x_{i}}$ , $\hat{y_{i}}$ , $\hat{w_{i}}$, $\hat{h_{i}}$ : network output에 다음과 같은 연산을 한 결과입니다.
network output 을 $t_{x}, t_{y}, t_{x}, t_{h}$ 라고하면,
$\hat{x_{i}}$ = $\sigma$ $(t_{x})$
$\hat{y_{i}}$ = $\sigma$ $(t_{y})$
$\hat{w_{i}}$ = $\exp$ $(t_{w})$
$\hat{h_{i}}$ = $\exp$ $(t_{h})$

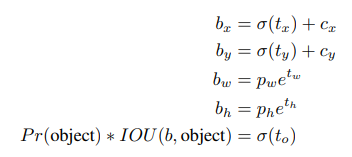
$C_{i}$ : 물체가 들어있는지를 판단하는 confidence 를 나타내는 부분입니다.
pr(object) * iou(prediction_bbox, gt_bbox) 로 구할 수 있으며,
pr(object) 는 1을 사용합니다.
$\hat{C_{i}}$ : network output에 다음과 같은 연산을 한 결과입니다.
5번째, network output 을 $t_{o}$ 라고하면,
$\hat{C_{i}}$ = $\sigma$ $(t_{o})$, size 는 [13, 13, 5] 입니다.
어떤 predictor 에 물체가 있는지의 여부를 0~1 로 표현해 출력한 값 입니다.
$p_{i}(c)$ : responsible 한 prediction 에 대한 one-hot 으로 encoding 된 classification label 입니다. [13, 13, 5, 20]
의 size 를 갖습니다.
$\hat{p_{i}(c)}$ : network output 마지막 부분에 softmax 를 사용하여 확률로 만든 출력값 입니다.
이제 loss 들의 의미를 하나하나 짚어봅시다.
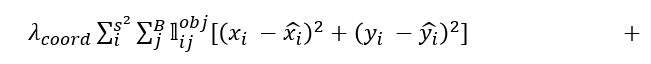
이 xy_loss 는 한 cell 내부의 존재하는 object 의 중점위치를 학습하게 합니다.

이 wh_loss 는 gt_bbox 와 anchor box의 w, h의 비율을 prediction 이 학습하게 합니다.
또한 제곱근을 사용하여 상자의 크기에대한 편차를 줄였습니다.

conf_loss 는 한 gt_bbox 와 pred_bbox 의 iou 를 줄여, 좀더 정확한 pred_bbox 가 나오도록 학습합니다.

no_conf_loss 는 object 가 존재하지 않는 부분의 iou 를 0으로 만들어서, background 를 알도록 학습합니다.

마지막으로 classification loss 는 클래스 구분을 학습하게 됩니다.
전체 loss 는 다음과 같습니다.
yolo 의 loss 들이 모두 sum square error 로 되어있는데, 이는 논문에서는 optimize 하기 쉬워서 사용했다고 합니다.
그러나 yolo v3 등으로 넘어가게되면, classification loss 는 sigmoid 등으로 변형이 되고, 여러 구현들도 마지막 부분을
그냥 cross entropy 을 사용하기도 합니다.
5. Train
yolo v2 는 여러가지 성능 향상의 이유를 제시하였습니다.
Batch normalization 을 사용하였고,
detection 에 사용하는 base network (darknet 19) classifier 를 학습할 때,
448 x 448 의 resolution 으로 fine-tune 을 한, High-Resolution Classifier 를 사용하였습니다.
그리고 anchor box 를 만들 때, VOC data 와 COCO data 를 유클리디언 거리가 아닌 제시한 iou 거리로
클러스터링을 통해서 만드는 Dimension Clusters 기법을 제시하였습니다.
그리고 convolution 과 anchor box 를 이용하고 anchor box 에서 prediction 을 각 cell 과 관련하여 loc 와 score
를 내주는 부분을 각각 Convolutional With Anchor Boxes, Direct location prediction 이라고 말하였습니다.
마지막으로 input image 를 320~608 의 다양한 (32 size) 10 개의 resolution 으로 두고 학습한 Multi-scale Training
방식을 제시하였습니다.
6. Evaluation & Results
이제 yolo v2 의 qualitative & quantitative result 에 대하며 말해보겠습니다. :)
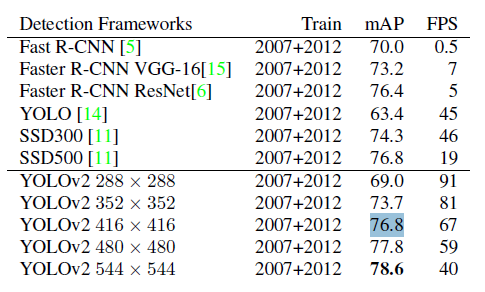
빠르고 높은 성능을 보여줍니다. 실제 논문이 나왔을 당시는 sota에 가까운 성능과 real-time 의 속도를 가지고 있어서
굉장히 주목을 많이 받았습니다.

voc 와 coco 의 결과를 보시면 voc 에서는 ssd보다 높은 성능을 보이는데, coco 에서는 좀더 낮은 성능을 보여줍니다.

Yolo v2 는 real-time one stage object detection 에 한 획을 그었으며 5000이 넘는 인용 횟수를 가지고 앞으로
더 오를것으로 기대됩니다.
많은 detection 들이 YOLO 의 아이디어를 가져오기 때문에 중요하다 생각하여 포스팅 하였습니다.
실제 코드는 다음을 참조하시면 좋을것 같습니다. :)
github.com/csm-kr/yolo_v2_vgg16_pytorch
csm-kr/yolo_v2_vgg16_pytorch
:octocat: re-implementation of yolo v2 detection using torchvision vgg16 bn model. - csm-kr/yolo_v2_vgg16_pytorch
github.com
+240217 추가)
reorg 설명 추가
아래에서 보면 2를 가진 차원을 앞으로 보내고, 중간에 64차원을 가지고 마지막 13 x 13 의 차원을 가진 텐서로 변환을 한다. 이는 그림과 같이 순서를 재배치 하여 차원을 늘리는 방법입니다.

'Object Detection > YOLO Detection' 카테고리의 다른 글
| [Object Detection] YOLOv4 리뷰 및 구현 (from YOLOv3) (0) | 2023.01.12 |
|---|---|
| [Object Detection] YOLO v3 논문리뷰 및 코드구현 (10) | 2021.04.19 |


댓글