
안녕하세요~ pulluper 입니다 :)
이번에는 YOLO v3에 대하여 분석및 리뷰를 해 보려고 합니다.
YOLO detection류는 one stage object detection 에서 빠질 수 없는 detection입니다.
앞으로 YOLO 의 version 이 어디까지 나오고 얼마나 개선이 이루어질지 궁금하네요.
아무튼! 시작해 보겠습니다.
참고로 YOLOv2 는 다음 포스팅을 통해 이해해시면 좋을것 같네요.
Yolo v2 리뷰 (CVPR2017)
안녕하세요 pulluper 입니다 :) 이번에는 one-stage detection의 시초라고 할수 있는 yolo 의 version 2 에 대하여 알아보겠습니다. yolo 라는 이름은 (you only look once) 의 줄임말인데요, 이 시기에는 Faster..
csm-kr.tistory.com
0. Introduction
논문은 다음과 같습니다 : arxiv.org/abs/1804.02767
YOLOv3: An Incremental Improvement
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that's pretty swell. It's a little bigger than last time but more accurate. It's still fast though, don't worry. At 320x320 YOLOv3
arxiv.org
이번에는 논문이라기보다는 tech report 라고 저자가 언급을 하고 있습니다.
실제로 읽어보면 원래 읽었던 논문 말고 더 재미나게 써져 있어요.
예를들어 다음과 같은 표는 표를 뚫고 나오는(?) 그래프를 그리기도 했습니다.
하지만 또다른 단점으로는 각잡고 만든 논문이 아니기 때문에,
세세한 details 들을 알기 어려웠답니다.
이런 부분은 실제 저자의 무려 c/c++ 로 만든 github.com/pjreddie/darknet
pjreddie/darknet
Convolutional Neural Networks. Contribute to pjreddie/darknet development by creating an account on GitHub.
github.com
에서 찾을수 있었습니다!
자 포스팅 내용은 크게, 다음과 같은 부분으로 알아보겠습니다.
- YOLO 의 정신
- Dataset
- Model
- Loss
- Training / Testing
1. YOLO 의 정신
YOLO의 가장 핵심적인 부분들을 말씀 드리고 싶어
이렇게 "정신"이라는 표현을 사용했네요!
여러 다른 anchor based detection 들과 비교하며
YOLO를 분석해본 결과 특별한 점을 찾을 수 있습니다.
1) YOLO 는 object 를 할당할 때, 단 하나의 anchor (bounding box prior) box 에 할당을 합니다.
논문에서는 2.1 Bounding Box Prediction 에서 설명을 하고 있습니다.
YOLO 는 object 를 할당할 때,
단 하나의 anchor (bounding box prior) box 에 할당을 합니다.
아래 그림을 보면 엄청나게 많은 anchor box 들이 존재하고,
detection 들은 학습을 위해서 어느 anchor 를 학습할 때
보아야 하는지 할당을 해야 합니다.
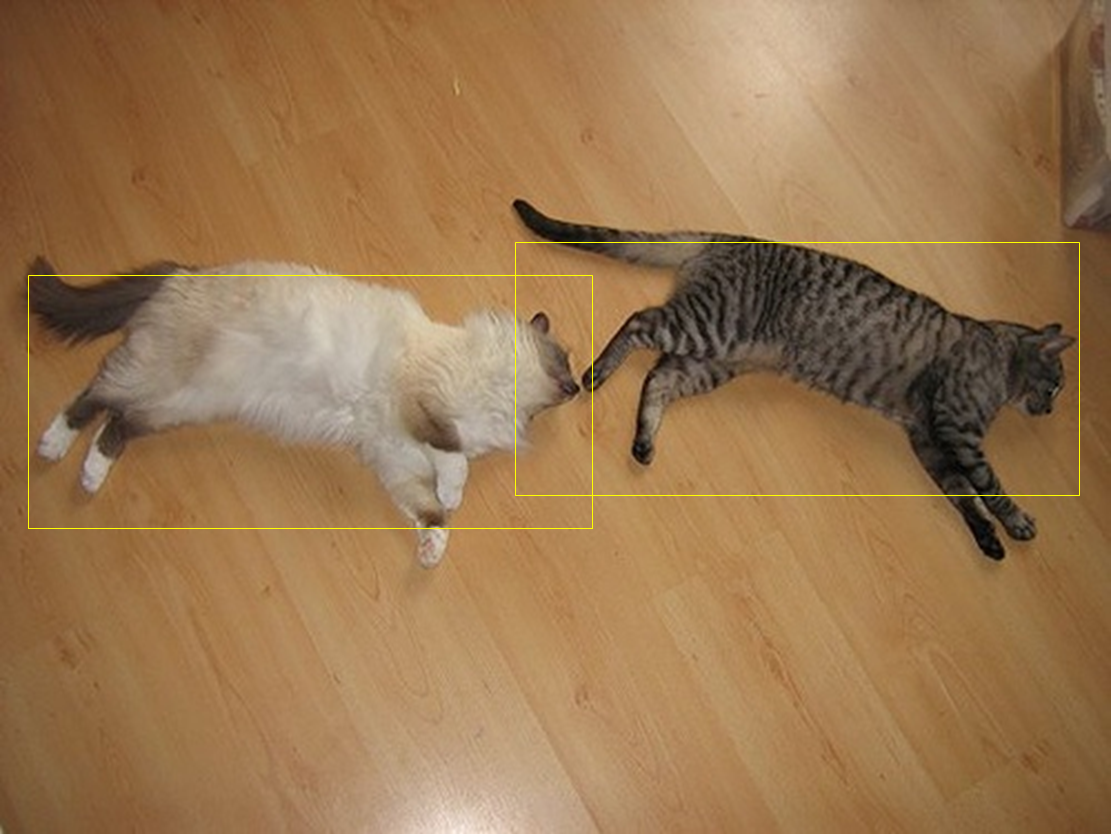
아래 그림에는 사람 4명과 보드 3개가 gt 로 있다고 가정하면,
YOLO 는 각 object 당 단 하나의 anchor 에 할당을 하여
positive anchor 로 사용하는 반면
다른 detection 들은 gt 와 anchor 간 iou 가 일정수준 이상(e.g. 0.5)이면
positive anchor 로 사용해서
학습시에 많은 anchor 들이 학습에 영향을 끼치게 됩니다.
그리고 결과를 보면 YOLO 류의 detection 들이 더 깔끔하게 (overlap 이 적게) object 를 찾아내는것 같습니다. 왜냐하면 위의 그림에서 yolo 는 학습 과정에서 단 하나의 가장높은 score 를 가지는 anchor 로부터 prediction 을 하지만 다른 detection 들은 prediction 이 positive 인 (iou 가 높은) anchor 가 YOLO 보다는 더 많은 정답을 가지고 있기 때문에 더 깐깐하게(harsh) 하게 보지는 않는다 라는 사실 때문인것 같습니다. 저는 이렇게 한 object 에 하나의 anchor 만 사용하는것이 큰 특징이라 생각하였습니다 :)
이렇게만 학습을 하면 학습이 어려울 수도 있지만, YOLO loss 에는 각 anchor 들이 objectness 인지 no objectness 인지 판단하는 term 이 있기 때문에, 학습이 가능합니다!
2) YOLO 는 Prediction 시 Grid 의 상대적인 위치로 bbox 의 위치를 찾아냅니다.
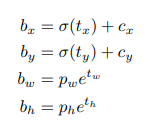
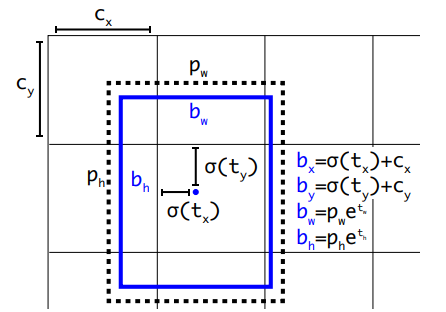
특이하게 xy 에 대한 prediction 할 때, (Grid) cell 안의 0~1 의 위치를 갖는것으로 학습을 하고 prediction 을 합니다.
wh 는 다른 논문과 같이, anchor 와 target w, h 에 대한 log scale 을 이용합니다.
논문의 뒷부분에서 다른 논문들과 같이 xy offset prediction을 anchor 들의 w 나 h 와 연관시켜 학습을 시킨 결과 모델의 안정성을 떨어뜨리고 잘 작동하지 않았다고 하네요.
이 두가지가 다른 일반적인 anchor based model 들과 차별화되는 yolo 만의 특성이라고 생각됩니다. :)
2. Dataset
dataset에 관해서는 논문에서는 COCO 를 이용한 benchmark를 사용했습니다. :)
VOC 는 점점 안하는 추세입니다. 아예 unsupervised learning 에서는 종종 사용하기도 하지만...
data augmentation 은 무엇을 이용했을까요?

많은... data augmentation 을 사용했다고 하네요.
YOLO v2 를 보면 아래와 같은 augmentation 을 했다고 하는데 YOLO v3 도 비슷합니다.
(random crops, rotations, hue, saturation, expisure shifts...)

3. Model
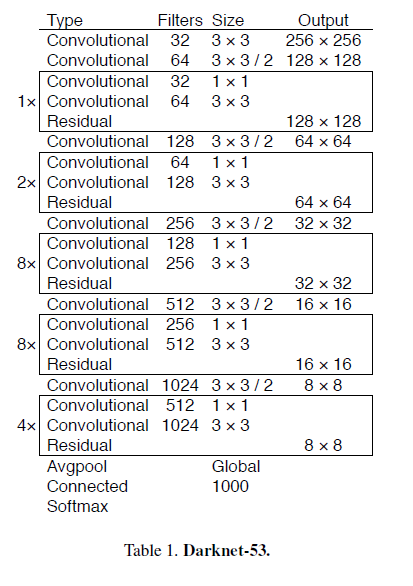
model은 backbone 이 Residual block 과 darknet 에 통합한 darknet 53 입니다!
이를 살펴보면 중간에 Residual 이라는 부분이 있습니다. 이는 다음과 같습니다.
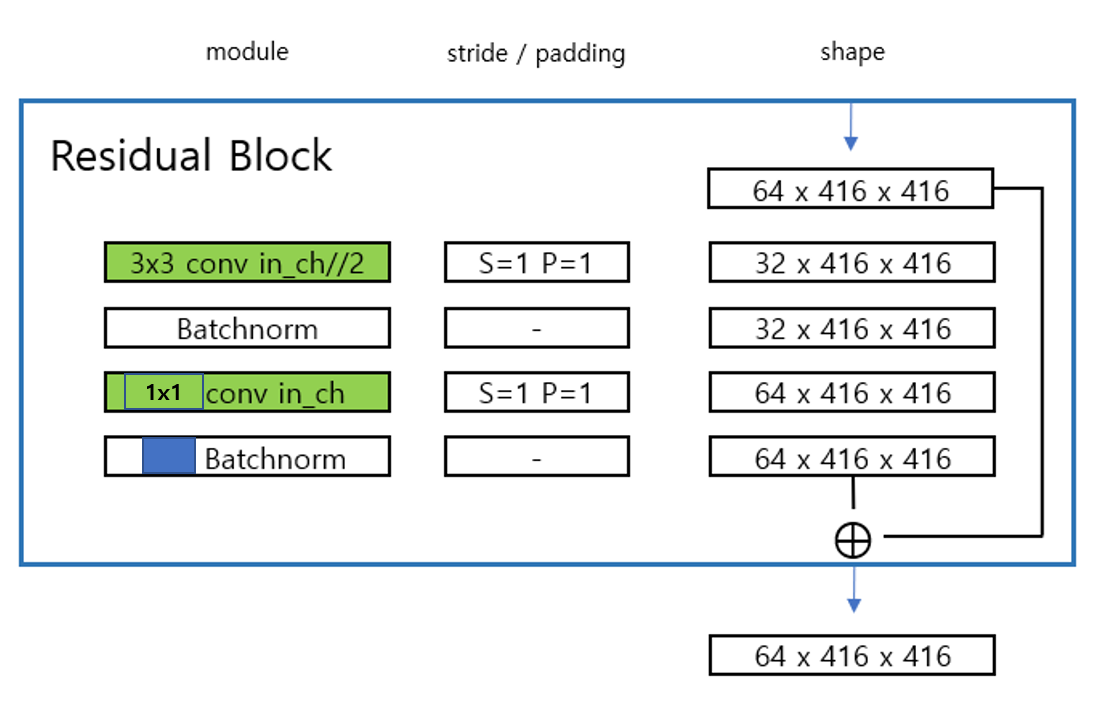
여기서 Residual Block 안에서도 bottleneck 구조를 사용합니다. 위 사진에서 오른쪽을 보면 input 의 shape 이 중간에서 한번 channel 이 반으로 줄었다가 다시 복구가 되면서 bottle neck 구조가 들어간 Residual Block 을 사용합니다.
결국 input shape 이 유지되는 하나의 모듈이라고 볼 수 있습니다.
다음 그림은 avgpooling 전까지의 Darknet 53 을 보여줍니다. 아래 그림에서의 각 초록색의 conv block 은 (conv-batchnorm-leakyrelu) 를 뜻하며 파란색의 Redisual block 은 위의 residual block 을 뜻합니다.
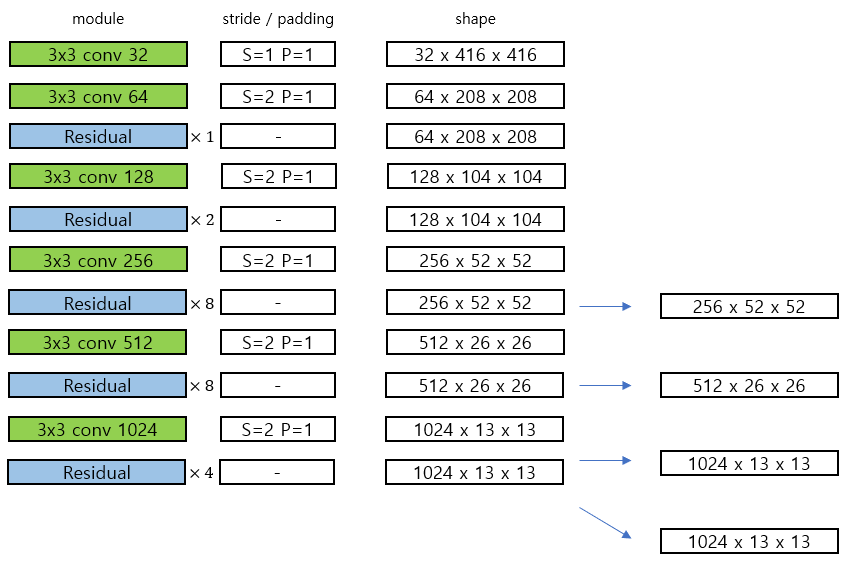
그리고 또 다른 특징은 YOLO v3 는 물체의 scale 을 고려하여 3가지 종류의 크기의 output이 나오도록, FPN 을 이용하여 네트워크를 설계 하였습니다. 위의 그림에서 오른쪽 4개의 feature 를 이용해 FPN(feature pyramid network) 를
다음과 같이 구성합니다.
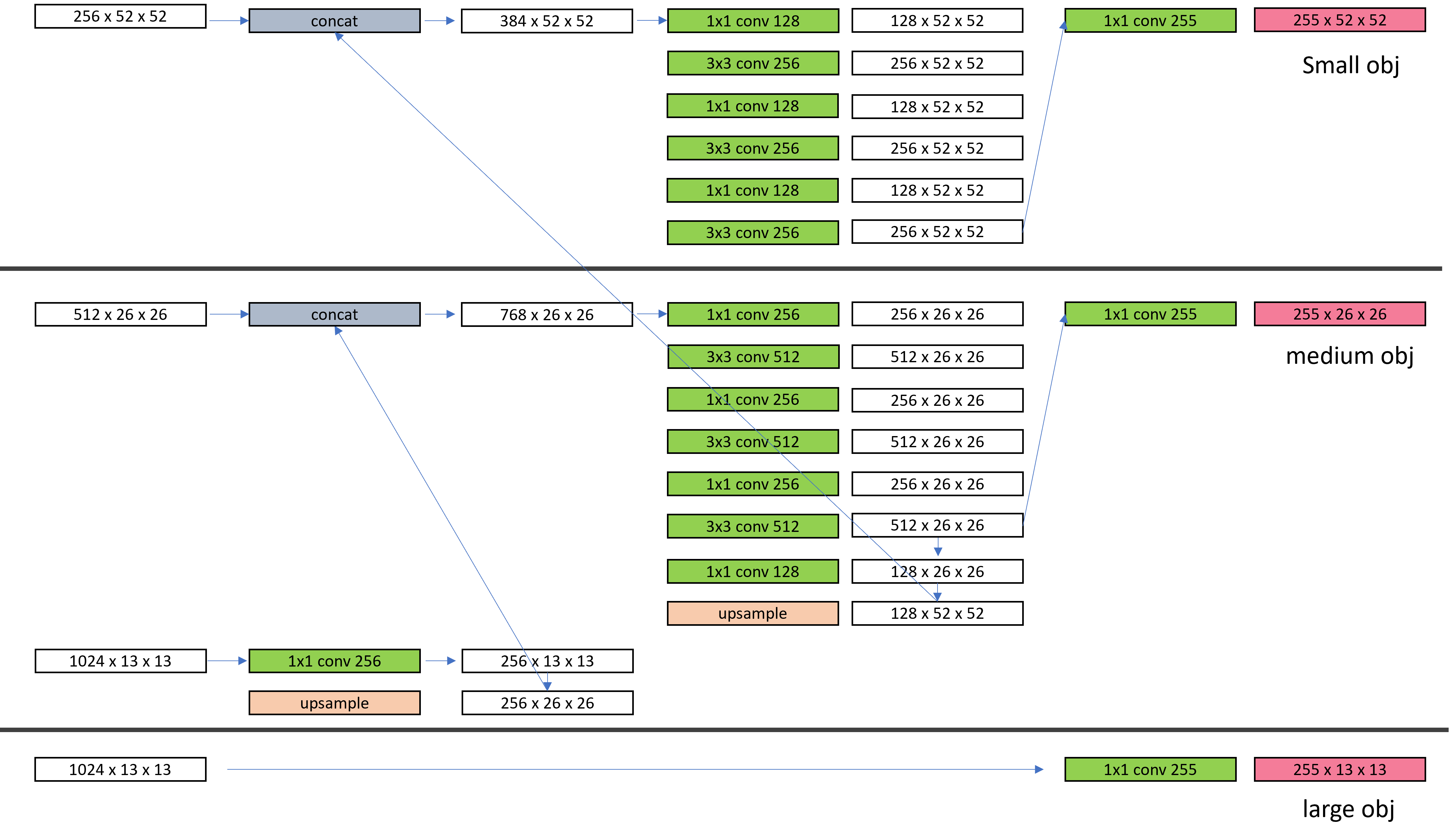
여기서 1x1 conv 는 s=1, p=0 이고, 3x3 con 는 s=1, p=1 입니다. 이렇게 아래에서부터 concatenation 을 통해서 small, medium, large 를 위한 feature map 들을 생성합니다.
이때 input 은 416 이고, dataset 은 coco 입니다.
feature 를 해석해 보자면, 일단 각 feature 의 shape 를 보면 됩니다.
[B x 255 x 52 x 52]
[B x 255 x 26 x 26]
[B x 255 x 13 x 13]
위에서부터 각각 small, medium, large 의 object 를 찾아내고자하는 output 입니다.
YOLO v2 에서 13, 13 의 feature 를 이용했던 부분도 포함합니다.
그럼 255 channel 은 무엇을 뜻하는지 알아볼까요
255 = (80 + 5) * (3) 을 뜻합니다. <-> (class 갯수 + [x, y, w, h, c]) * (anchor 의 갯수)
이렇게 Yolo v3 의 model 인 Darknet 53 은 [B, 3, 416, 416] 의 이미지를 넣어서
3가지 종류의 ([B x 255 x 52 x 52], [B x 255 x 26 x 26], [B x 255 x 13 x 13]) output 을 내는 것을 알 수 있습니다.
4. Loss
Deep neural network, 특히 supervised learning 에서의 loss 는 parameter 를 학습하는 목적(objective)/기준 등의 역할을 합니다 loss 를 작아지게 하면, 원하는 task 의 성능이 높아지도록 설계를 합니다.
loss 는 2가지의 요소가 필요합니다.
하나는 ground truth (정답값) 입니다.
다른 하나는 네트워크의 output ,즉 prediction (예측값) 입니다. 보통 예측값은
object detection 은 classification 과 localization 이 합쳐진 형태의 task 이므로, 물체를 classification 하는 부분과 물체의 위치를 예측하는 부분으로 학습이 진행됩니다.
개념적으로, YOLO v3 의 ground truth 는 (
그럼 저 x, y, w, h, o, c 가 의미하는 바는 무엇일까요? 그리고 어떻게 만들 수 있을까요?
본격적으로 loss 를 보기 이전에 loss 에 필요한 ground truth 를 만드는 부분과 anchor box 에 대하여 알아보겠습니다.
1) Anchor boxes
먼저 anchor boxes 입니다. anchor box 는 pre-define 된 object를 탐지하기 위한 box 입니다.
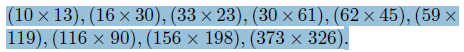
anchor size 는 다음과 같이 구성되어 있으며 3개씩 나누어 small, medium, large 에 맞는 anchor 를 구성하였습니다.
(10 x 13), (16 x 30), (33 x 23) - small
(30x 61), (62 x 45), (59 x 119) - medium
(116 x 90), (156 x 198), (373 x 326) - large
이렇게 구성한 이유는 coco 에 대한 clustering 으로 9개의 anchor 를 구하였다고 합니다.
결국 scale 별로 나눠진 3가지 anchor 는 model 에서 나온 3 종류의 output 과 각각 loss 를 구하게 됩니다.
2) ground truth 만들기
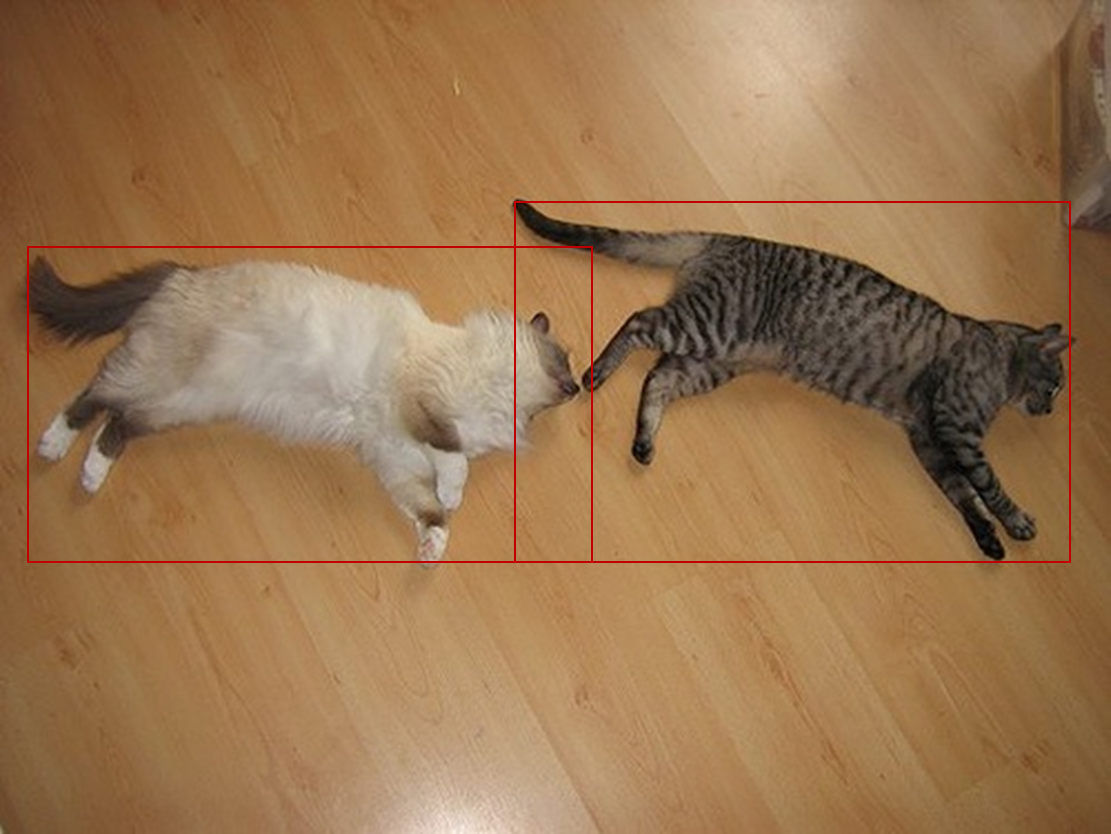
detection에서의 정답을 알려주는 annotation 은 .xml 파일이나, .json 파일등 여러가지 포멧으로 저장이 되어있는데, 여기에 들어있는 정보는 object 의 class 와 위치 (x1, y1, x2, y2) or (x1, y1, w, h) 등.. 이 포함됩니다.
아래 그림은 voc 2007 dataset 의 xml 파일인데, 이것을 parsing 해서 우리가 원하는 class 와 location 정보를 얻어 올 수 있습니다.


여기서 주어지는 정보는 class 는 [cat, cat] 이고 이들의 location 은 [[231, 88, 483, 256], [11, 113, 266, 259]] 라는 정보 입니다. 이제 class 는 정해진 label 값으로 변경하면 되고 (예를들어 [7, 7]), location 정보는 (x1, y1, x2, y2) 의 format 인데, [[231, 88, 483, 256], [11, 113, 266, 259]] 로 가져옵니다.
location 을 바로 loss 에 적용시킬 수 있을까요? 아쉽게도 아닙니다. 😰
이 location 을 detection 의 ground truth 로 변환시키는 과정을 encoding 이라고 하며, 이는 알고리즘마다 조금의 차이가 있습니다. 여기서 anchor 의 개념이 함께 들어가기 때문에 detection 의 loss가 약간 복잡해지는 것입니다.
그렇다면 yolo v3 의 location gt (
1 | pre-define 된 box (anchor box) 와 location 간의 IOU 를 구한다. (yolo v3 는 clustering 으로 bbox 를 미리 구해놓음)
아래의 왼쪽의 노란색 box(anchor box) 와 진짜 location 을 표현하는 오른쪽의 빨간 box 와의 iou 를 구합니다.

2 | yolo 는 한 물체당 하나의 anchor 를 할당하는데, 여러 anchor 들 중 가장 큰 iou 를 갖는 값을 할당을 합니다. 또한 yolo 는 cell 을 기준으로 location 을 정하는데 오른쪽 그럼과 같이 초록색으로 된 (5, 3), (8, 3) 의 cell 안, 특정 anchor 내부에 object 가 존재한다는 정보를 알 수 있습니다.

3 | 할당 한 anchor box 에 대하여 다음 식을 적용합니다.
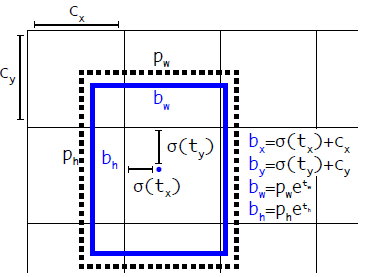
x, y - cell 내부의 0~1 사이의 값.
w, h - box의 값을 anchor 의 값으로 나눈값의 log (gt box 와 anchor 간의 log space 비율)
[[231, 88, 483, 256], [11, 113, 266, 259]] 의 location 값을 원래 이미지를 고려하여 0~13 사이로 resize 를 시키면
[[6.07 ,3.05, 12.56, 8.87], [0.29, 3.92, 6.92, 8.98]] 이 나오고,
여기서 두번째 object 에 대하여 (0.29, 3.92, 6.92, 8.98)
assign 된 anchor 를 [4.875 , 6.1875] 이라고 하면 다음과 같이 GT 를 만들 수 있습니다.
GT 는 위의 식에서
아래 수식으로 구할 수 있습니다.
bx - cx = 0.29
by - cy = 0.92
log(bw/pw) = log(6.92/4.875) = 0.350
log(bw/pw) = log(8.98/6.1875) = 0.372
할당이 되지 않은 anchor 는 나중에 loss 에서 masking 으로 영향을 끼치지 않게 설정되므로, 아무 값이나 지정해 주어도 됩니다.
(보통 0 등으로 값을 지정해줍니다.)
4 | SIZE 별 location GT 설정
YOLO 가 cell 기준으로 GT 를 만들기 때문에, 13 x 13 의 cell 이 있다면, 각 cell 안에는 3 개의 anchor box 가 들어있고, 그 중에서 할당된 anchor 에는 3 과 같은 연산을 통해서 값이 들어가고 그렇지 않는 경우에는 0으로 둡니다.
따라서 [13, 13, 3, 4] 의 location 에 관한 GT 를 할당합니다. 그런데 YOLO 는 3가지 scale 의 anchor 와 network output 이 존재하기 때문에, [26, 26, 3, 4], [52, 52, 3, 4]의 medium, small 을 위한 GT 도 만들어집니다.
따라서 한 이미지에 대하여 [13, 13, 3, 4] , [26, 26, 3, 4], [52, 52, 3, 4] 의 location Grond Truth 를 만들어 냅니다.
5 | objectness 와 class 의 구성
이제, 각 cell 에 관한, anchor 에 관한 x, y, w, h 는 만들어졌습니다. 그렇다면 o (objectness) 는 어떻게 만들어질까요?
2| 에서 할당되는 anchor 와 bbox 의 iou 가 가장 큰 anchor 의 값이 1 그렇지 않은 경우의 값이 0 인 [13, 13, 3, 1] 의 tensor 가 o 로 만들어집니다. class label c 는 one-encoding 으로 [13, 13, 3, num_classes] 의 shape 을 갖는 tensor 로 만들어 질 수 있습니다.
3) YOLO v3 Loss
드디어 YOLO v3 의 Loss 에 대하여 알아볼 시간입니다.
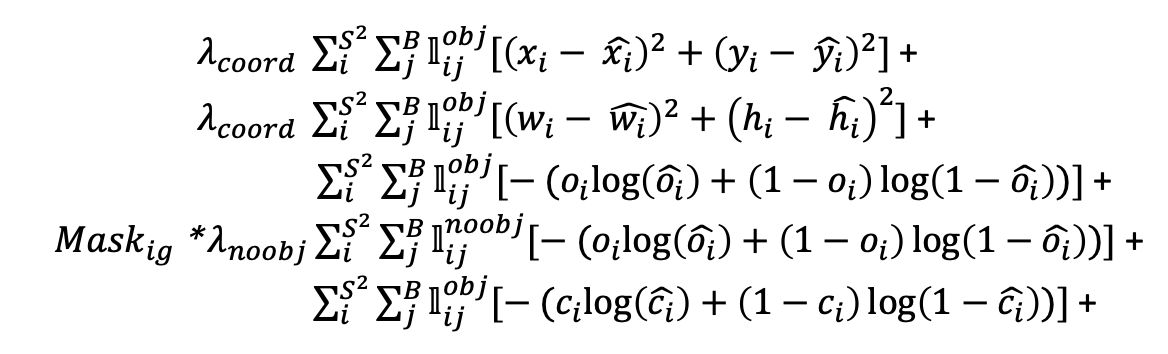
기본적으로는 YOLO v2 loss 와 비슷하지만 몇가지 다른 점이 있습니다.
먼저 objectness , no objectiveness, classification loss 가 모두 binary cross entropy 를 사용했다는 점 입니다.
x, y, w, h에 관한 loss 는 여전히 sum squre error 를 사용했습니다.
S : number of cells - cell 의 갯수
B : number of anchors - anchor 의 갯수 (3)
종합적으로 위 loss 를 3가지 scale 에 대하여 모두 진행하였습니다.
전체 loss 의 의미를 생각해보면, objectness 와 no objectiveness loss 에서 object 가 어디 존재하는지를 알면서,
classification 과 location regression 을 하는 것으로 볼 수 있습니다. 😋
5. Training / Testing
Training 환경은 다음과 같습니다.
- optimizer : SGD, (weight decay : 0.0005, momentum : 0.9)
- initial learning rate : 1e-3
- batch size : 64
- training iteration : 500000
- learning rate decay : Step LR (400000, 450000)
Testing
- COCO test-dev 를 사용했으며, 준수한 성능을 보입니다.
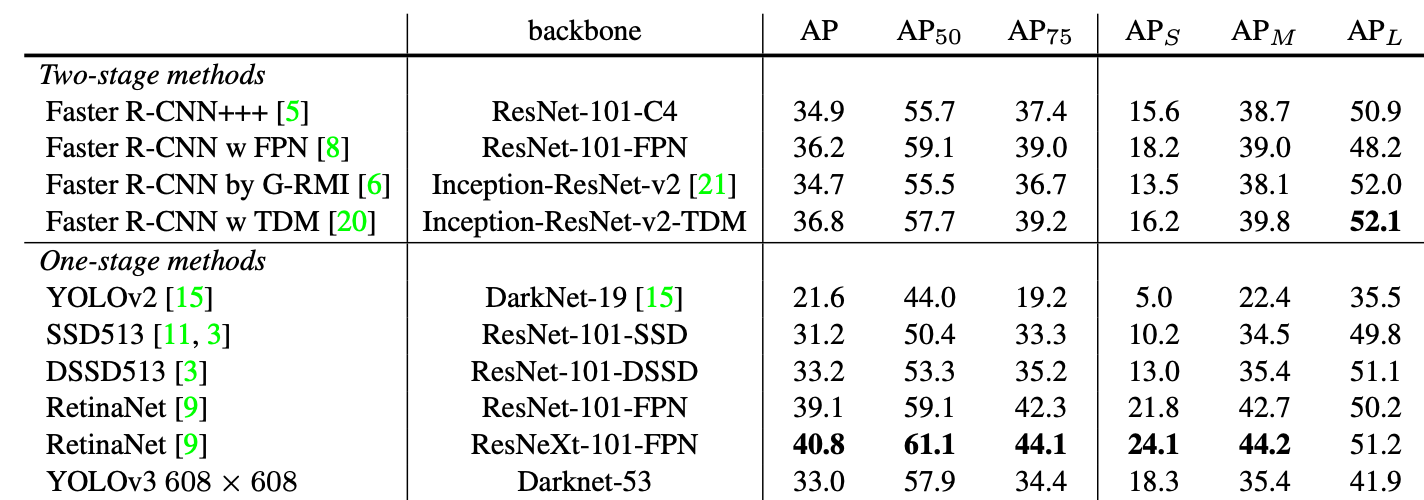
- YOLO v3 의 mAP-50/time(1/fps)
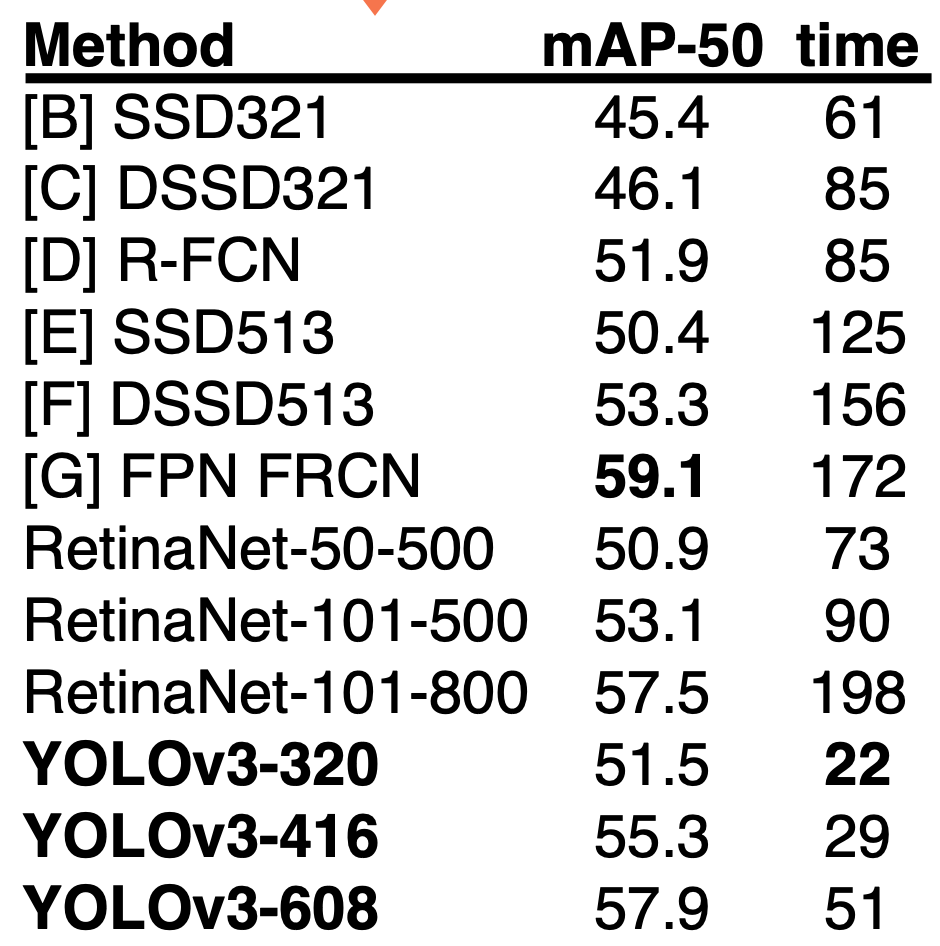
속도도 빠르면서 mAP-50 부분에서는 retinanet 을 넘어서는 성능을 보여줍니다. 누군가가 YOLO v3 는 AP 가 타 detection 에 비해서 낮다 라고 하였습니다. 이에 저자는 반박하는 모습을 보여주기도 하였습니다. Joseph Redmon 은 이번 yolo v3 를 마지막으로 자신의 기술이 군사적 목적으로 사용되는게 싫다고 컴퓨터 비전 연구를 그만 두겠다고 하였습니다.
다음 블로그에 저자의 정보와 rebuttal 에 대한 정보가 잘 정리되어 있습니다 :) (감사합니다)
https://darkpgmr.tistory.com/179
YOLO와 성능지표(mAP, AP50)
최근에 YOLO 논문들을 보다 보니 저자가 2018년 YOLOv3를 마지막으로 YOLO 연구를 중단한 것을 알게 되었다. ☞ 그리고 올해 2020년 2월 자신의 twitter를 통해 컴퓨터비전 연구를 중단한다고 선언한다. YO
darkpgmr.tistory.com
이번에는 YOLO의 3번째 version 인 리뷰를 진행 해 보았는데요.
간단한 방식을 사용해서 성능을 크게 높인것이 인상 깊었습니다.
필자가 직접 구현한 YOLO v3 에 대한 코드는 다음과 같습니다.
↓ 구현 코드 ↓
https://github.com/csm-kr/yolo_v3_pytorch
GitHub - csm-kr/yolo_v3_pytorch: re-implementation of yolo v3
:blossom: re-implementation of yolo v3 . Contribute to csm-kr/yolo_v3_pytorch development by creating an account on GitHub.
github.com
의견이나 질문은 댓글 부탁드릴께요.
감사합니다. 😝
'Object Detection > YOLO Detection' 카테고리의 다른 글
| [Object Detection] YOLOv4 리뷰 및 구현 (from YOLOv3) (0) | 2023.01.12 |
|---|---|
| [Object Detection] YOLO v2 논문리뷰 및 코드구현(CVPR2017) (8) | 2020.07.16 |


댓글