안녕하세요. pulluper 입니다. :)
최근 torchvision을 둘러보니, 2023년 5월 기준 version이 main (0.15.0a0+282001f) 까지 나왔습니다.

최신 version의 torchvision에서 제공하는 object detection은 다음과 같습니다.
(segmentation, keypoint detection 등도 존재..torchvision 짱.. 😍😘)

이 중에서 faster rcnn의 종류는 다음과 같습니다.
원래 사용한 backbone인 vgg16 은 없고,
resnet50_fpn과 mobilenet_v3_fpn에 대한 모델들이 있네요.

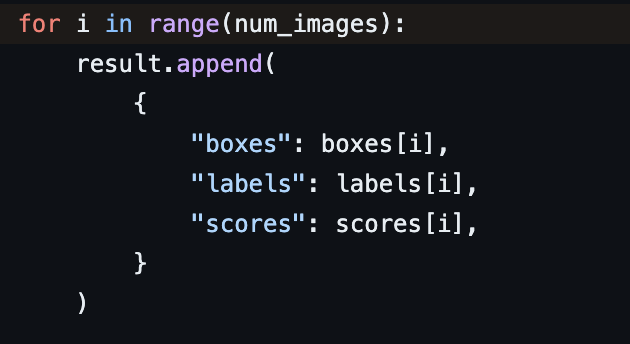
torchvision detection model의 output인 pred은 다음과 같은 형태를 갖습니다.
https://github.com/pytorch/vision/blob/main/torchvision/models/detection/roi_heads.py#L777
GitHub - pytorch/vision: Datasets, Transforms and Models specific to Computer Vision
Datasets, Transforms and Models specific to Computer Vision - GitHub - pytorch/vision: Datasets, Transforms and Models specific to Computer Vision
github.com
따라서 pred에서 batch를 제거하고 각 결과를 가진 dict을 이용해 쉽게 detection result를 뽑아 낼 수 있습니다. 예제는 축구를 하는 마라도나님를 이용 해 보겠습니다. ⚽️

다음은 demo 라는 함수로 torchvision fasterrcnn_resnet50_fpn model
을 이용해서 예측 박스, 레이블, 스코어를 가져오는 함수입니다.
pretrained는 COCO dataset 으로 되어있습니다. (classes = 91)
threshold는 기준 스코어로 이 점수를 넘는 박스만 출력하도록 합니다.
또한 이미지의 정규화가 object detection 에는 없는것이 특징입니다. (다음 이슈 참고)
https://github.com/pytorch/vision/issues/2397
Normalization for object detection · Issue #2397 · pytorch/vision
Migrated from discuss.pytorch.org. Requests were made by @mattans. 📚 Documentation The reference implementations for classification, segmentation, and video classification all use a normalization t...
github.com
def demo(img_path, threshold):
# 1. load image
img_pil = Image.open(img_path).convert('RGB')
transform = T.Compose([T.ToTensor()])
img = transform(img_pil)
batch_img = [img]
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.eval()
pred = model(batch_img)
# 2. remove first batch
pred_dict = pred[0]
'''
pred_dict
{'boxes' : tensor,
'labels' : tensor,
'scores' : tensor}
'''
# 3. get pred boxes and labels, scores
pred_boxes = pred_dict['boxes'] # [N, 1]
pred_labels = pred_dict['labels'] # [N]
pred_scores = pred_dict['scores'] # [N]
# 4. Get pred according to threshold
indices = pred_scores >= threshold
pred_boxes = pred_boxes[indices]
pred_labels = pred_labels[indices]
pred_scores = pred_scores[indices]
# 5. visualize
visualize_detection_result(img_pil, pred_boxes, pred_labels, pred_scores)
결과사진입니다. 😀

전체 데모 및 시각화 코드는 다음과 같습니다.
다음 깃헙에서 전체 코드 및 사진을 참조 하실수 있습니다. 🥰
↓ 구현 코드 ↓
https://github.com/csm-kr/torchvision_fasterrcnn_tutorial/blob/master/demo.py
감사합니다.
Reference
https://github.com/spmallick/learnopencv/blob/master/PyTorch-Mask-RCNN/PyTorch_Mask_RCNN.ipynb
https://github.com/csm-kr/retinanet_pytorch/blob/master/demo.py
'Object Detection' 카테고리의 다른 글
| DiffusionDet 뿌시기 (Deep Dive) (0) | 2025.10.30 |
|---|---|
| 도커환경에서 ultralytics yolo v11 학습 및 검증 (0) | 2025.01.16 |

댓글