안녕하세요 pulluper 입니다.
오랜만에 논문리뷰를 하려 합니다. 오늘 리뷰할 논문은 SAM(segment anything) 입니다.

Introduction
Paper : [Link], Github : [Link], Project : [Link]
2023년 4월 FAIR 에서 작성한 논문으로 제목부터 '어느것이든 분할하겠다' 라는 의지를 표명합니다.
2024년 1월 현재 1600 이상의 citation 이 있고 ICCV2023에서 발표 되었습니다.
아카이브 버전부터 아주 관심이 많았던 논문입니다.
본래 인식문제는 미리정의된 (pre-defined) 클래스와 위치 (bbox, mask 등)를 찾는 것이 목적인 task 인데,
SAM에서는 promptable segmentation 을 task 로 잡습니다.
promptable segmentation 란 '마스크로 생성하고자 하는 대상으로 prompt 로 지정하여 생성하는 task 입니다.
prompt로 사용되는 것은 점들 (points), 박스 (bbox), 텍스트 (text) 등이 있습니다.
비슷한 task로는 zero-shot segmentation 등이 있을 수 있습니다.
왜냐하면 한번도 안 본 대상을 (여기서 클래스를 뜻합) segmentation해 내야 하기 때문입니다.
따라서 기존의 미리 정해진 클래스를 푸는 문제보다 더 어려운 문제입니다.
이번 리뷰는 논문의 흐름과 비슷하게 Task, Model, Dataset, Experiment에 대하여 작성을 해 보겠습니다.
그럼 시작하겠습니다.
Task
[Vision의 Foundation model 을 향해서]
LLM(Large Language Model)의 성능과 능력은 zero-shot, few-shot 생성을 모두 가능하게 합니다. (chat gpt)
chat gpt 는 다음과 같은 느낌의 "foundation model" 입니다.
"foundation model"은 학습때 데이터의 그 분포를 넘어서 생성 가능하게 하는 모델이며, 훨씬 더 일반적 이라고 할 수 있습니다. 이러한 일반화 능력인 수용력(capacity)은 prompt engineering 통해서 만들어집니다.
NLP(Natural Language Processing)에서의 prompt engineering 은 "높은 품질의 응답을 얻어 낼 수 있는 prompt 입력값들의 조합을 찾는 작업" 이라고 할 수 있습니다. 여기서는 prompt 를 설정하고 segmentation을 하기위한 foundation model 만듭니다. 즉, 이 논문의 목표는 image segmentation 에서의 foundation model 을 prompt engineering 이용해서 만드는 것이라 합니다.
[Promptable Segmentation]
여기서 다루는 Task 는 promptable segmentation 입니다. 처음 이 말을 들었을 때, vision 에서의 prompt 가 무엇인지 궁금해 졌습니다. language에서의 prompt 는 어떤 말뭉치 들이라고 할 수 있겠지만, vision 에서의 prompt 는 무엇일까요?
논문에서는 prompt를 물체를 구별해 낼 수 있는 공간적, 언어적 정보 라 합니다.(spatial or text information identifying an object) 예를 들어 아래 그림과 같이 점들(points), 박스(bbox), 마스크(mask), 나아가 텍스트(text) 로 볼 수 있겠습니다.
1) image encoder & prompt encoder
2) Decoder & TwoWayTransformer
이번에는 디코더를 알아볼 차례입니다.
2-1) set features
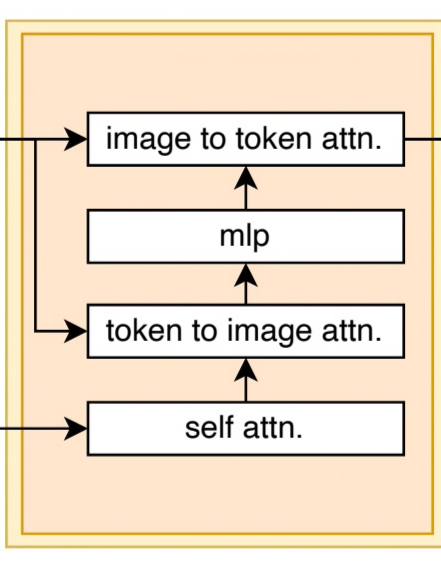

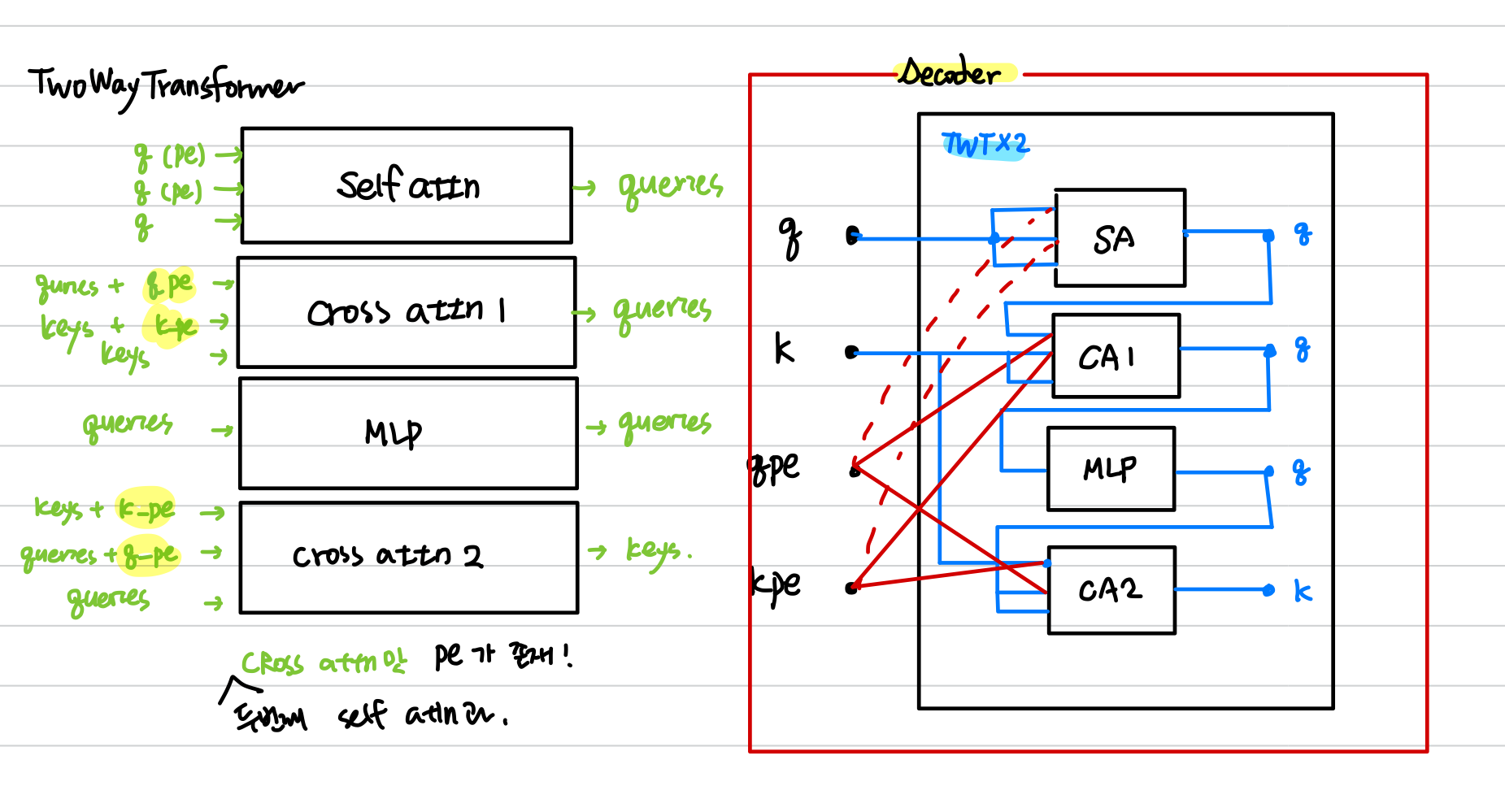
2-2) TwoWayTransformer
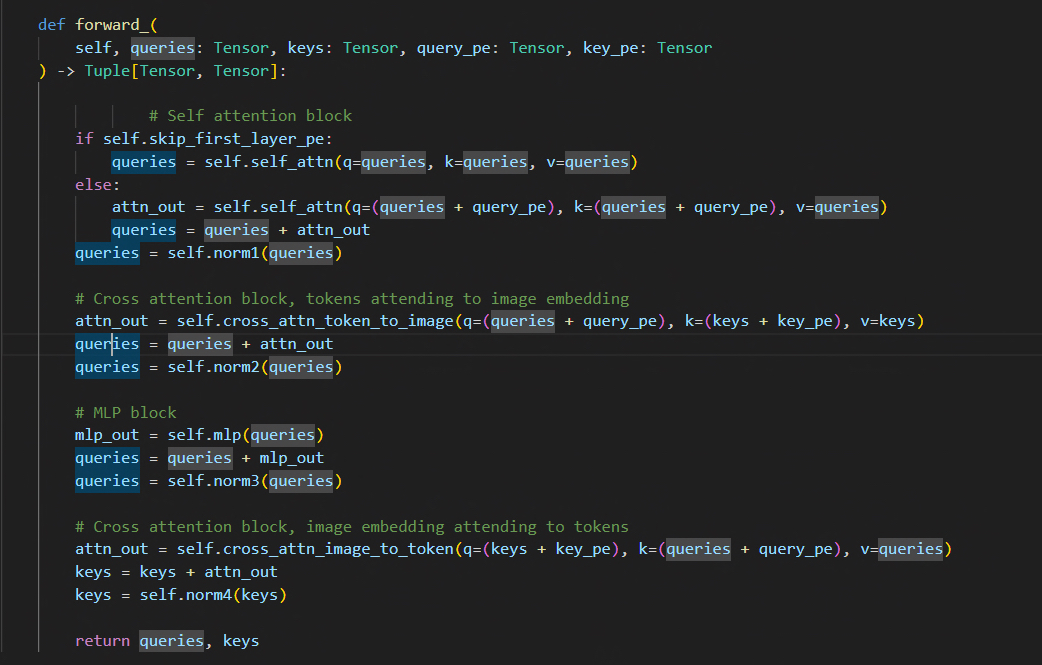
변경한 코드
댓글